第一章——基础
修补世界
怎么解释0mq呢?有的人会说它做的都是很神奇的事。它是各个不同部分的接口。它就像会转发的邮箱。它很快!其他人试着分享他们来灵感的瞬间的那种兴奋。事情变得很简单,复杂的都跑了。它打开了脑洞。其他人通过对比来解释。它更小,更简单,但是看起来更有亲和力。我自己呢,我更想一直记着我们为什么开发zmq,因为那时候我就处在读者你们现在所在的位置上,看着复杂的世界。
程序是披着艺术外衣的科学,只是我们大多数都不理解软件并且很少人会教导我们。软件不是算法、数据结构、语言或者抽象,这是只是我们制造、使用、丢弃的工具。真正的软件就是人本身——特别是当到一定复杂度后我们的限制,还有我们把大问题划分为小问题共同来解决的愿望。程序科学就是:制造人们能理解并且易用的东西,然后人们就可以在一起工作来解决大型问题了。
我们生活在互联的世界里,现代的软件必须为我们提供导航。所以制造那些解决将来大问题的软件需要互联的和大规模并行的。现在对代码来说仅仅“健壮并沉默”是不够的。代码必须会跟代码交谈。代码必须是健谈的、社会性的、互联的。代码必须像人的大脑那样,亿级的单体神经细胞相互交换着信息,无控制中心的超大规模并行网络,没有单点失效,并且能解决超大规模的问题。毫无疑问代码的将来就像是人类的大脑,因为所有的网络归根结底都可以算是人类大脑那一层级的东西。
如果你已经用线程、协议或者网络做了一些东西,你就会意识到上边所说的会是多么的不可能。那是个梦。当你着手模拟一个现实生活中的例子的时候,一个用socket连接的小程序都是相当麻烦的。至于亿级的?这些开销会是无法想象的。通过软件和服务去连接每个电脑很麻烦,而且是个上百亿的大生意。
我们生活在一个线缆远超我们使用它的能力的世界。1980年我们有一场软件危机,导致像Fred Brooks等一些软件工程师相信“没有银弹”以“保证大规模提高软件的生产效率、可靠性和简单”。
Brooks错过了自由和开源的软件,而正是开源解决了这场危机,让我们能有效的分享知识。今天我们面对的是另一场软件危机,关于这场软件危机我们并没有很多的讨论。只有大型富有的公司才有能力构建互联应用。虽然有云,但云是私有的。我们的数据和知识都从我们的个人电脑消失进入云端,我们够不着也无法操作。谁拥有我们的社交网络?这种情况看起来像是倒退到了大型主机的时代。
我们把政治哲学留给另一本书。它的观点是尽管互联网提供了大量潜在的互联代码,但现实远远超过我们大多数人的控制,并且还有那么多有意思的问题(在健康,教育,经济,运输等领域)没办法解决,因为这些领域并不能跟代码互联,也就没办法跟大脑相连来共同工作解决问题。
已经有很多试着解决代码互联挑战的努力了。有成千的IETF规范,每个解决这个问题的一部分。对应用程序开发者来说,HTTP协议可能是相当容易干活儿的一个解决方案了,但它总是鼓励开发者和架构师优先考虑那种大型服务器——瘦蠢客户端的模式,这让问题变得更麻烦了。
所以今天人们仍在用原始的UDP和TCP,私人协议,HTTP和网络socket。使用这些个东东一如既往让人觉得痛苦、慢、很难控制规模,并且本质上仍是中心控制的。分布式的P2P框架很大程度上是为了玩,而不是工作。有多少应用程序使用skype或者BitTorrent去交换数据的?
这些让我们重回编程科学,为了修补世界,我们需要做两件事。第一,解决传统的“怎么去让任何代码随时随地连接另外的任意代码”的问题。第二,把那些东西包装起来,给人们提供简单明了的工具。
从假设开始
我们假设你正在使用不低于3.2的zmq。我们假设你正在用个linux的小盒子或者一些类似的东西。我们假定你多多少少读得懂c代码,因为那是提供的例子的默认语言。我们假定当我们写下像PUSH或者SUBSCRIBE这样的常量的时候,你能想象出来它们在程序里叫ZMQ_PUSH或者ZMQ_SUBSCRIBE。
问就应当有回应
让我们从一些代码开始。我们用hello world开始课程喽。我们要写个client和一个server,client发送hello给server,后者就回复world。下面是用c写的server,它在5555端口打开一个zmq socket,从其上读取请求,然后给每个请求回复“world”:
1 | //Hello World server |
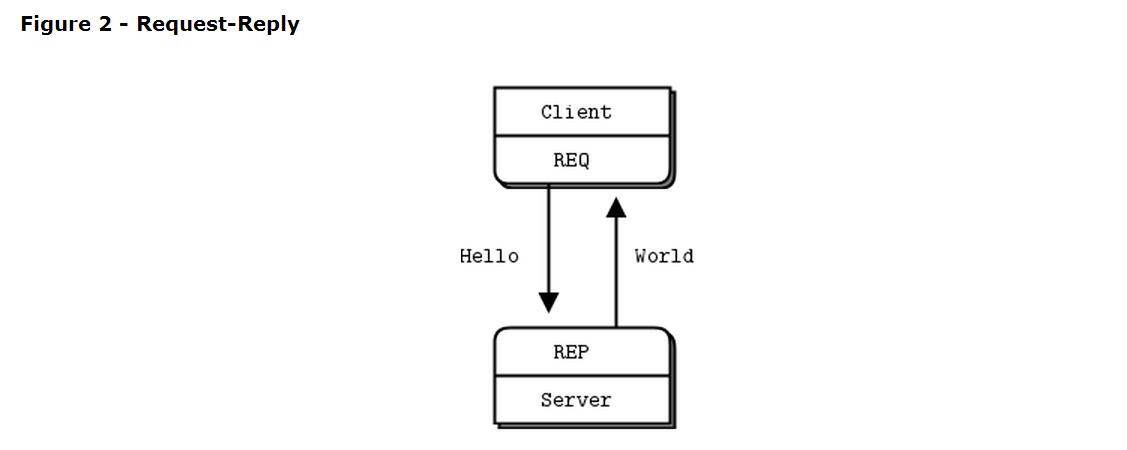
REQ-REP套接对是完全同步的。Client在一个循环中(或者只是处理一次)依次处理zmq_send()和zmq_recv()。做任何其他的队列(比如连续发送两个messages)将会导致send或者recv调用返回-1。类似的,server会在循环中依次处理zmq_recv()和zmq_send()。
Zmq用c作为参考语言,并且这也会是我们用作例子的主要语言,如果你在线读这个指南的话,例子下边会有不同语言的链接。
接下来是client的代码:
1 | // hwclient: Hello World client in C |
现在看起来实现着这么容易,但zmq socket有着超级能力。你可以同一时间丢给server成千上万个client,并且server还能工作的轻松加愉快。另外,试着先启动client然后再启动server,看看它是否还在正常工作,想想这意味着什么。
让我们稍微解释下这两个程序到底怎么在工作的。他们创建了一个zmq 的上下文(context)和一个socket。不用担心这些词是什么意思,你会知道的。Server绑定它的REP(reply)socket到5555端口,然后server在一个循环中等待request,再然后每次都回复一次。Client发送请求并且读取从server来的回复。
如果你杀掉server(Ctrl-C)并重启它,client不会正常的恢复,从崩溃的进程中回复并不容易,写个可靠的请求——应答流很复杂,我们会在第四章去讲。
这个场景的背后还有很多事情发生,但我们程序员最关心的代码是否精简美妙,在高负荷下崩溃的频率。这是请求——应答模式,可能是使用zmq最简单的途径了。它涵盖了RPC和传统的client/server模型。
对字符串的简单注解
Zmq不知道你发送的数据内容,只知道它的大小。这意味着你有责任组织数据,以便程序能读取出来。针对对象和复杂数据类型的组织,是一些特殊的类库(比如protocol buffer)做的事情。但是甚至只是string类型,你也需要小心。
在c或者其他语言中,string以一个空字节结尾。我们可以发送一个带空字节的类似“HELLO”的字符串:
zmq_send(requester, “Hello”, 6, 0);
然而,如果你从另外一种语言发送一个字符串,它可能不包含空字节。例如,当我们用python发送同一个字符串,我们这样做:
socket.send(“Hello”);
然后这个字符串在电缆上传送的是一个长度和作为独立字块的字符串内容。
如果你从一个c程序中读取这个东西,你会得到一个看起来像字符串的东西,但是可能只是恰好是一个字符串(只是恰好5个字节之后跟了一个空字节),但是这不是一个正好的字符串。当你的客户端和服务器端在字符串格式上不统一时,你就会得到很奇怪的结果。
当你在c程序中从zmq收到一个字符串数据时,你不能相信它就有一个空字节。每一次你读到一个字符串时,你应该另外申请一块多一个字节的内存,把收到的字符串复制过去,并自己在内存结尾手动加一个空字节。
现在让我们定下来使用zmq 字符串的规矩:zmq的字符串是用长度定义的,在电缆上传输时没有空字节结尾。在最简单的情况下(稍后我们会在自己的例子中用到这些),一个zmq字符串正好对应着一个zmq message帧,这个帧就像上图所示的那样——一个长度和一些字节。
这里就是在c中我们需要做的,收到一个zmq字符串,把它转换成一个有效的c字符串传递给应用:
1 | // Receive 0MQ string from socket and convert into C string |
这里我们写了一个很有用的函数,并且更好的是我们可以复用它。让我们再写个相似的s_send函数来正确的发送string,并把这些函数放在我们可以复用的头文件中。
结果就是zhelpers.h文件,让我们可以用c写出更美妙的更短的zmq程序。它有点儿长,并且只有c程序员对它有兴趣,可以闲时读读。
版本报告
Zmq有几个不同的版本,如果你碰到一个问题,它经常会在下个版本中得到解决。所以知道你在使用的库文件的版本会是个很有用的技巧。
这里有个短小精悍的程序做这个工作:
1 | // Report 0MQ version |
把信息提取出来
第二种经典模型是单向数据分发,这种模型中一个服务器向一系列的客户端推送升级信息。我们来看一个推送包括区号、气温、相对湿度的天气预报的例子。我们用随机数来模拟真的气象台做的那样:
1 | // wuserver: Weather update server in C |
在更新的数据流中没有开始和结尾,就像一个没有尽头的广播。
下面是一个客户端程序,它监听更新的数据流并且根据特定的区号提取出相应的信息,New York City是个开始冒险的好地方:
1 | // wuclient: Weather update client in C |
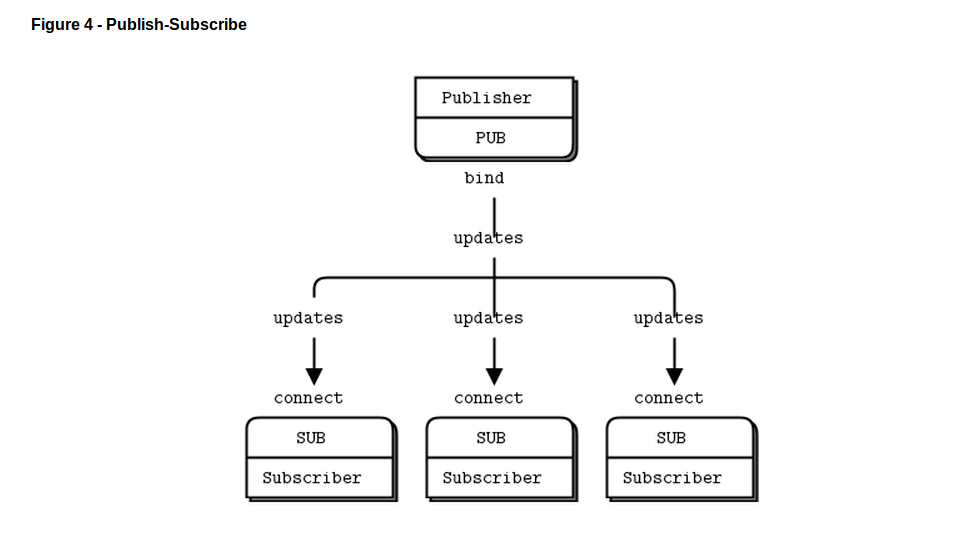
注意当你用SUB套接字的时候你必须用zmq_setsocketopt()和SUBSCRIBE设置一个订阅的信息,就像这个代码中做的那样。如果你不设置任何的订阅信息,你得不到任何messages.这对初学者来说是个常犯的错误。订阅者可以设置很多的订阅信息,这些信息会叠加在一起。如果一个更新的数据匹配到任何订阅信息,订阅者就可以收到它。订阅者也可以取消特定的订阅信息。一个订阅信息经常——但也不一定非要是——一个可打印的字符串。
PUB-SUB套接对是异步的。客户端只管在一个循环中(或者只是一次)用zmq_recv()接收。向一个SUB套接字发送信息会引发错误。类似的,服务器端需要发送多少信息就做多少次zmq_send(),但是禁止在PUB套接字上用zmq_recv()接收信息。
在zmq socket的理论中,谁connect、谁bind都无所谓。但是,我稍后会说一些在实际中没有明文规定的关于connect和bind的差别。现在呢,就在PUB bind,在SUB connect就好,除非你的网络设计让它失效。
关于PUB-SUB套接对还有一点需要注意:你不能确切的知道一个订阅者什么时候能开始得到信息。甚至你先启动订阅者,等一会儿,然后再启动发布者,订阅者总会丢失发布者分发的最初的信息。这是因为在订阅者连接到发布者的时候(这事儿时间很短但不是0),发布者就已经把信息发送出去了。
这种“慢参与”现象迷惑了很多人,这我们接下来详细的说明。记住zmq是后台异步的东西。比如你有两个节点在做这件事,顺序是:
- 订阅者连接到一端接收信息并计数
- 发布者绑定到一端然后立即发送1000条数据。
然后订阅者很可能收不到任何信息。你可能迷瞪一下,检查是否设置了正确的过滤器然后重试,但是订阅者还是没收到任何东西。
TCP用三次握手创建一个连接需要几毫秒的时间,这个时间取决于你的网络和两端点之间的跳数。在那段时间中,zmq可能已经发送了很多信息。比如说TCP花费了5毫秒建立了一个连接,相同的连接可以每秒处理1M的信息。在这5毫秒中订阅者连接到发布者,这花费发布者1毫秒的时间把1K条信息全部发送出去。
在第二章——socket和模式中我们将解释如何同步订阅者和发布者,让发布者在订阅者已经建立起来连接并且准备好接收数据后再去发布数据。延时发布者的发布行动有个简单但很笨的方法,就是让它睡一会儿。但是别在实际程序中这么做,因为这中系统相当的脆弱,不优雅也很慢。用sleep去验证会发生什么,然后等到第二章再去看如果正确的处理这种情况。
同步处理的一个替代方法是假定分发的数据流是无穷的,没有开始也没有结束。订阅者也不关心在它开始接收数据前都蒸发了哪些数据。我们在天气预报的例子中就是这么做的。
客户端的订阅者选择它自己的区号并且收集100条相应的更新数据。如果区号是随机分布的,这就意味着从服务器端分发了差不多1000,000条数据。你可以先启动客户端,然后再启动服务器端,客户端会正常工作。你可以随时停止和重启服务器端,客户端还保持正常工作。当客户端收集到足够的数据时,它就计算平均值,打印出来,然后退出。
关于PUB-SUB模式的一些点:
- 一个订阅者可以连接多于一个的发布者,每次使用一个连接。数据交错到达(使用公平队列算法),以保证不会让单独的发布者淹没其他的发布者。
- 如果发布者没有一个订阅者连接,它就简单的丢掉所有的信息。
- 如果你使用TCP,订阅者速度(网速或者处理速度)又很慢,信息就会在发布者那里堆积起来。我们稍后会看到如何用“高水位线”保护发布者。
- 从zmqv3.x版本开始,当使用一个连接协议(tcp: or ipc:)时,过滤器在发布者那端。使用epgm://协议时,过滤器在订阅者那端。在zmq v2.x版本中,所有的过滤器都在订阅者一端。
下面是该程序在我的笔记本上从接收到过滤10M信息所用的时间,我的笔记本是2011年的 Intel i5,还好但并不特别的处理器:
1 | $ time wuclient |
分发跟合并
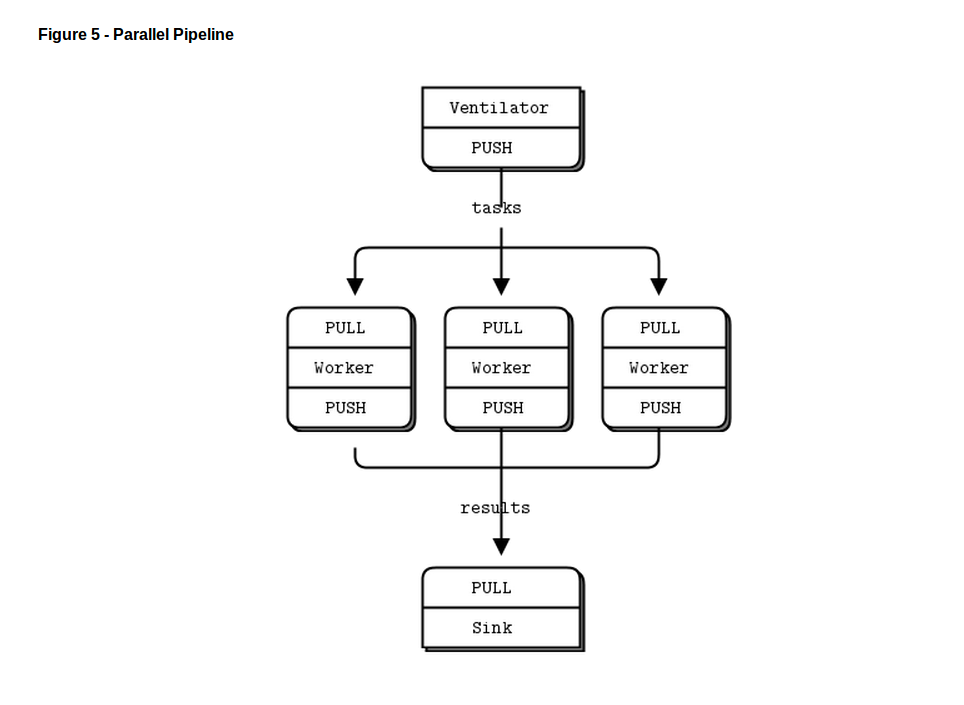
最后一个例子(你肯定已经厌倦了鲜嫩多汁的代码,想深入了解关于zmq的抽象规范的理论了),让我们做一些超级运算。然后喝杯咖啡。我们的超级运算应用是一个相当典型的并行计算模型。我们有:
- 一个产生能并行计算任务的ventilator
- 一套处理任务的workers
- 一个从worker处理流程中手机结果的sink
实际中,workers运行在超级快的盒子中,可能是用GPU(graphic processing units)去做很难的数学运算。下面是ventilator的代码,它产生100个任务,每个信息告诉worker睡几毫秒:
1 | // taskvent: Parallel task ventilator in C |
下面是worker的代码,它收到信息,睡上几秒,然后发出信号说它完成工作了:
1 | //taskwork: Parallel task worker in C |
这里是sink的代码,它收集100个任务,然后计算出任务总共花了多长时间,所以如果有超过1个worker的话,我们就能确定workers就是并行的运行的:
1 | //tasksink: Parallel task sink in C |
一批任务的平均耗时是5秒,当我们启动1,2,4号workers时我们会从sink得到如下的结果:
1 | 1 worker: total elapsed time: 5034 msecs. |
让我们更细致的看看这些个代码:
- workers向上连接ventilator,先下连接sink。这意味着你能随意增加workers。如果让workers绑定到的端点,每次当你添加一个worker时你就需要(a)有更多的端点和(b)修改ventilator 和/或sink的代码。在我们的架构中称ventilator和sink为固定部分,workers为动态部分。
- 我们必须同步批作业的启动和所有workers启动、运行情况。这在zmq中是个常见的情况,并且没有简单的解决办法。Zmq_connect() 方法需要花费一定的时间,所以当一系列的workers连接到ventilator时,在极短的时间内第一个成功连接的worker会得到所有的任务负载,其他的还在连接中。如果你不用某种方法同步批作业的启动,系统根本不会并行运行。试试去掉ventilator中的wait,看看会发生什么。
- ventilator的PUSH socket 平均的分发任务到各个workers(假设他们都在批处理启动前就已经连接好了)。这叫负载均衡,稍后我们会更详细的说明。
- sink的PULL socket 会从workers平均的收集结果。这叫公平队列。
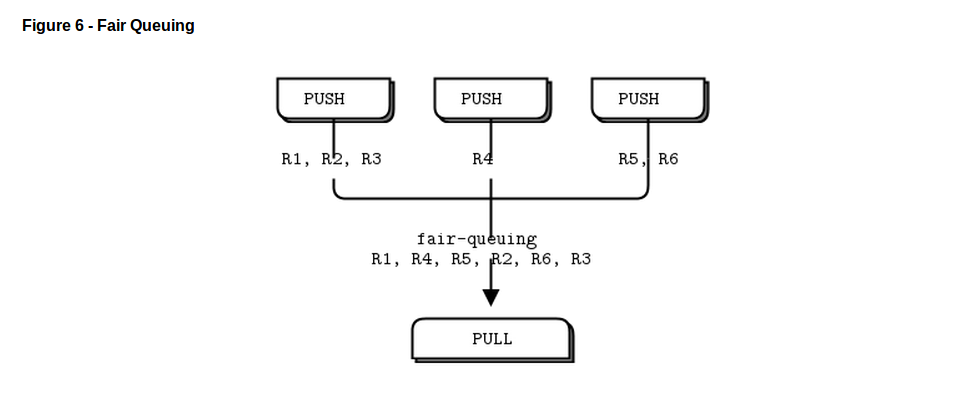
管道模型也会呈现“慢参与”现象,导致PUSH socket并不会正确的进行负载均衡。如果你要用PUSH 和 PULL,而且workers中的一个得到了更多的信息,那是因为这个PULL socket比其它的更早参与进去,在其它socket建立好连接之前抓取了大量的信息。如果你想正确的进行负载均衡,你可能向看第三章的负载均衡模式。
用zmq编程
已经看了几个例子,你肯定很想在程序中使用zmq。在你开始之前,深呼吸,淡定,然后来看一些能减少你压力和疑惑的基本建议:
- 一步一步来学zmq。它虽然只是一些简单的API,但隐藏了超级多的(能力)坑。慢慢的一个个掌握这些能力(慢慢填坑)。
- 写出漂亮的代码。丑的代码会隐藏很多问题,也很难让别人帮助你。你可能对无意义的变量名熟悉了,但是读你代码的人并不熟悉。使用真实世界中的名称,而不是“我对告诉你这个变量名代表什么无所谓”。使用一致的缩进和干净的布局。写些漂亮的代码,你的世界会变得更美好。
- 在你制造的时候检查你制造的东西。当你的程序不工作时,你需要知道哪五行代码是错的。对zmq来说这特别正确,你在最初几次使用的时候往往不会正常工作。
- 当你在找不正常工作的代码时,把你的代码分解开来,一个一个检查,看哪个没有工作。Zmq让你能写出模块化的代码,让这成为你的优势吧。
- 在你需要的时候就尽量抽象(类、方法、不管什么)。如果你复制/粘贴了很多代码,你也复制/粘贴了很多错误。
得到正确的上下文(context)
Zmq应用总是从创建上下文开始,然后用它来创建socket。在c中,zmq_ctx_new()做这件事。你应该在你的进程中确切的创建使用一个上下文。专业点儿说,上下文(context)是一个线程中所有socket的容器,也是inproc socket的交通工具,inproc socket是一个进程中各个线程之间最快的传递信息的方式。如果在运行时一个进程有两个上下文(context),这就像分开的zmq实例。如果那正是你要的东西,ok,但另外请记住:
在main函数开头用一个zmq_ctx_new(),就要在代码结尾使用一个zmq_ctx_destroy()。
如果你使用了fork(),每个线程需要它自己的上下文。如果你在main函数中在调用fork()之前使用了zmq_ctx_new(),子进程会得到他们自己的上下文。通常来说,你希望在子进程中做一些有意思的事情,而在主进程中管理这些繁琐的东西。——注:这里是段奇怪的描述。
干净的退出
优秀的程序员分享的那些优秀的座右铭是:当你结束工作的时候就收拾干净。当你在python那样的语言中使用zmq,这些琐事都已经自动为你做好了。但是当你用c的话,当你不再使用他们的时候你必须小心的清理掉这些对象,否则就该出现内存泄露,不稳定的应用,不好的后果。
内存泄露是一个方面,但是zmq真的很介意你是怎么退出程序的。原因是有原因的,最关键的是如果你把socket都打开放到那儿,zmq_ctx_destroy()函数就永远挂到那儿了。甚至当你关掉所有的socket,zmq_ctx_destroy()默认也会永远挂到那儿等着是否有连接进来或者发送数据,除非你在关掉它们之前设置LINGER为0。
我们关心的zmq的对象有message, socket, context。幸运的是它们都很简单,至少在简单的程序里边很简单:
- 使用
zmq_send()和zmq_recv(),这会使你避免操作zmq_msg_t对象。 - 如果你用了
zmq_msg_recv(),在你用完它之后尽快用zmq_msg_close()释放掉。 - 如果你打开和关闭很多的socket,说明你需要重新设计你的应用了。一些情况下socket在你销毁上下文之前不会被释放掉。
- 当你退出程序,关闭socket然后调用
zmq_ctx_destory(),它会销毁上下文。
这至少是c开发的情况。那些能自动销毁对象的语言会自动帮你销毁socket和context的。如果你使用异常的“final block”去做清理工作,那就一直去这样做。
如果你在做多线程的工作,情况会变得更复杂。我们会在下章接触多线程,但是因为你们中的一些人可能会忽略警告、在会走之前就准备跑起来,下面是一些快速、不完善的说明,让你在多线程应用中干净的退出。
首先,不要在多个线程中试着使用同一个socket。不要解释你认为这有多吊,仅仅是不要这么做。然后,你在关掉正在进行请求的socket的时候,正确的做法是设置一个低的LINGER值(1秒),然后再关掉socket。如果你使用的语言不能在你销毁一个context时自动处理这些,我建议你发一个bug。
最后,销毁context。这会使那些在attached线程(共享context的东西)中阻塞的receive、poll、send都返回一个错误。捕捉这些错误,设置好Linger,在那个线程中关掉socket,然后再退出。不要销毁一个context两次。在context知道的所有socket都安全关闭之前,主线程中zmq_ctx_destroy()会阻塞住。
哈!接下来这句不会翻译啦。It’s complex and painful enough that any language binding author worth his or her salt will do this automatically and make the socket closing dance unnecessary.
为什么需要zmq
现在你已经见识了zmq,让我们回过头来谈谈“why”。
现在的许多应用都由通过网络几个部分组成,不管是局域网还是互联网。那么多的开发者做的都是某种信息的传输工作。一些开发者使用消息队列产品,但更多的时间他们用TCP或者UDP玩自己的。这些协议用着不是很难,但是要从a到b发送信息,做一些可靠的保证,就相当困难了。
让我们看看在用原始TCP连接不同部分的时候遇到的典型问题。任何可用的信息传输层都需要解决下面全部或部分的问题:
- 我们怎么操作I/O?让应用阻塞住,还是我们在后台去处理I/O?这是一个关键的设计选择。阻塞I/O会产生不可良好扩展的架构,但是后台I/O真的很难做好。
- 我们怎么处理动态的组件,比如那些能暂时挂掉的部分?我们要形式上把组件划分为“clients”和“servers”,命令服务器端不能挂掉吗?我们要把服务器和服务器连接的时候要怎么办呢?我们会每几秒重连一次吗?
- 在电缆上我们怎么表示一个message?我们怎么组织数据,让它容易写容易读,避免缓冲溢出,对小数据高效,对那些有带着舞会帽跳舞的猫的视频的大数据又能轻松的处理?
- 对不能立即发送的数据我们怎么处理?特别的,我们是否要等待一个组件重连上来?我们是丢掉数据,还是把它们存到数据库,还是扔进内存队列中呢?
- 我们在哪儿存储message队列?如果组件从一个队列中读取数据很慢,造成队列堆积会发生什么呢?那时候我们的策略是什么?
- 我们怎么处理丢失的message?我们是等待新的数据,还是要求重传,还是我们再造一个安全的层以保证数据不会丢失?如果那个层自己挂掉了又怎么办呢?
- 如果我们需要使用另一个不同的网络传输协议会怎么样呢?比如说,用多播协议代替TCP?或者IPv6?我们需要重写应用,还是在某些层网络传输是透明的?
- 我们怎么路由message?我们能把同一个message发送给多个对端吗?我们能给发出请求的对端正确的回复吗?
- 我们怎么给另一种语言写API?我们要重新设计一个报文级协议还是封装在一个库中?如果是前者,我们怎么保证有效性和可靠性?如果是后者,我们怎么保证互通性?
- 我们怎么处理网络错误?我们是等待重试,还是忽略它们,还是中断呢?
拿hadoop zookeeper做个典型的例子,读一下它在src/c/src/zookeeper.c的c API。当我在2013年1月读它的时候,它是神秘的4,200行东西,里边有一个没有正式文档的、客户端/服务器通信的协议。我认为它是有效的,因为它使用了poll而不是select。但是真的,zookeeper应该用一种通用的信息层和一个确切的报文协议。一遍遍重复的造相同的轮子对团队来说是极大的浪费。
但是怎么造一个可用的传输层呢?为什么那么多项目需要这项技术,但是人们还是在他们的代码中用TCP socket做这些工作,一遍遍去解决上边长长列表中的问题呢?
很显然构建可复用的消息传输系统是很困难的,这就是为什么很少开源软件项目去尝试,也是为什么那些商用的消息传输系统很复杂、很昂贵,同时也没有弹性、很脆弱的原因。在2006年,iMatix公司设计了AMQP,它开始给开源软件开发者提供可能是第一个可复用的消息传输系统。AMQP比很多其他的设计工作的更好,但是仍然相当复杂、昂贵、脆弱。它要花费几周去学习怎么用,要花费几个月去构建稳定的不会崩溃的架构。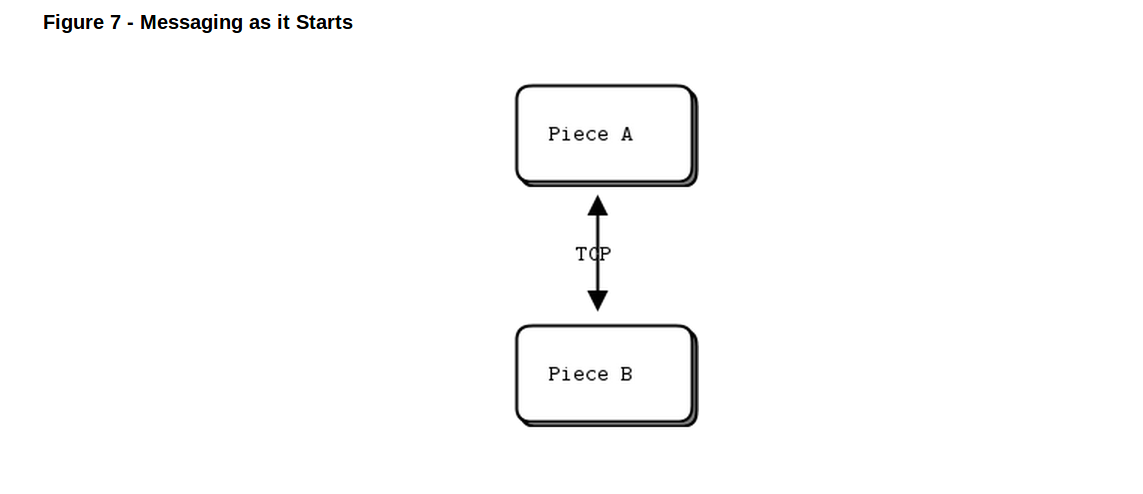
大多数的信息传输项目,像AMQP,试着通过发明一个新的概念——“broker”——来解决上边那个长长的问题列表,这个broker做的工作就是定址,路由,排队。这导致了一种client/server的协议或者在那些让应用能跟borker交流的无正式文档定义的协议之上的一整套API。Borker在减少大型网络项目中是一个极好的东西。但是增加像zookeeper那样的基于borker的信息传输系统可能会让事情变得更复杂。它意味着要增加一个附加的大箱子,一个新的单点错误。Broker很快成为瓶颈和新的管理风险。如果软件支持它,我们可以增加第二个、第三个甚至第四个broker,制造出一些备援模式。人们就是这么做的。它创造出更多可移动的部分、更复杂,打碎更多的东西。
另外,一个broker为中心的系统需要它自己的操作团队。你要时刻监视着这些broker,一旦他们不正常工作,你就要敲打敲打他们。你需要很多装置,也需要很多后备装置,也需要很多人手去管理这些装置。用很多可移动的部分、由几个团队的人打造好几年构建出来一个大型应用是很值得的。
中间件应用开发者总是陷入很小的模块开发中。不管他们是避免网络编程只去做集成应用而不去做大规模的设施,还是他们跳进去网络编程去制造那些脆弱的、复杂的很难维护的应用,还是他们把赌注放在一个消息传输产品、最终生产出依赖昂贵的、易出现问题的计数的大规模应用。没有真正很好的选择,这就是为什么信息传输还处在上个世纪中,这也激起了强烈的情绪:让使用者受挫,但对那些卖支持和专利的人来说是天大的好事。
我们需要的就是做信息传输工作的东西,但是它是否使用一种很简单的很廉价的方式工作在任何应用中,接近0开销。它应该是个库,你只需要链接,而没有其他依赖。没有附加的可移动部分,所以没有附加的风险。它应该跑在所有系统上,跟所有编程语言都对接。
这就是zmq:一个有效的、嵌入式的库,能解决一个应用在网络上完美传输信息的0开销的库所遇到的大部分问题的东西。
特别是:
- 它在后台线程中异步处理I/O。这些沟通各个应用的线程使用无锁数据结构,因此并行的zmq应用不需要锁、信号量或者其他等待状态。
- 组件能动态的随去随来,zmq将会自动重连。这意味着你可以用任意一种顺序启动组件。你可以开发出“service-oriented architectures”(SOAs)的架构,服务可以在任何时候添加进来或者删除。
- 在需要的时候它自动让信息排队。它很智能的做这些事情,在让信息排起队前会尽量发送信息。
- 它让你的应用能用任意一种传输协议交流:TCP,多播,进程内,进程间。你不需要改变代码就能用一种不同的传输协议。
- 使用依赖不同信息模式的不同策略,它能安全的处理 slow/blocked reader。
- 它让你可以使用很多不同的模式去路由信息,比如说request-reply和pub-sub模式。这些模式就是你开发的拓扑结构、网络架构。
- 它让你能在一个调用中创建排队、前推或捕获信息的代理。代理能减少复杂网络内部的连接。
- 它使用简单的帧结构,保证信息完整的传输。如果你写了10k的message,你就会收到10k条。
- 它不对信息格式做任何要求。他们不管是0字节还是成G的数据,都是可以的。当你希望表示数据的时候就使用其他产品,比如msgpack,google的protocol buffers等。
- 当它检测到网络错误的时候会自动重试,聪明的去处理这些错误。
- 它减少了二氧化碳排放。使用更少的CPU做更多的事意味着你的盒子只需要更少的能源,你可以接着用很长时间那些旧盒子。Al Gore(美国总统,爱好环境保护)会喜欢zmq的。
事实上zmq比上边这些做的更多。它在你开发网络应用上有着颠覆性的影响。表面上,它就是你用的zmq_recv()和zmq_send() 等socket 的API,但是信息传输处理进程很快变成了循环,你的应用也很快分解成各种信息处理工作。它是优雅的和自然的。它也是可扩展的:每一个任务都映射到一个节点上,这些节点通过任意传输层跟其他节点沟通。两个节点在一个进程中(节点是一个线程),两个节点在一个盒子中(节点是一个进程),或者两个节点在一个网络中(节点是一个盒子)——它都是一样的,没有太多的代码要改。
Socket的可扩展性
让我们实际看看zmq的扩展性。这里有个shell脚本启动天气预报的服务器和一组并行的客户端:
1 | wuserver & |
在客户端运行时,我们用top命令看一下这些运行的进程,我们会看到这些东西(在4核机器上):
1 | PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND |
让我们再看一次这里发生了什么。Weather服务器只有一个socket,我们用5个客户端向它并行发送数据。我们可以有成千上万个并发的客户端。服务器端看不到他们,也无法直接跟他们沟通。因此zmqsocket有点儿像服务器,尽可能快的安静的接收客户端的请求,然后向它们发送数据。并且它是个多线程服务器,能压榨出更多的CPU性能。