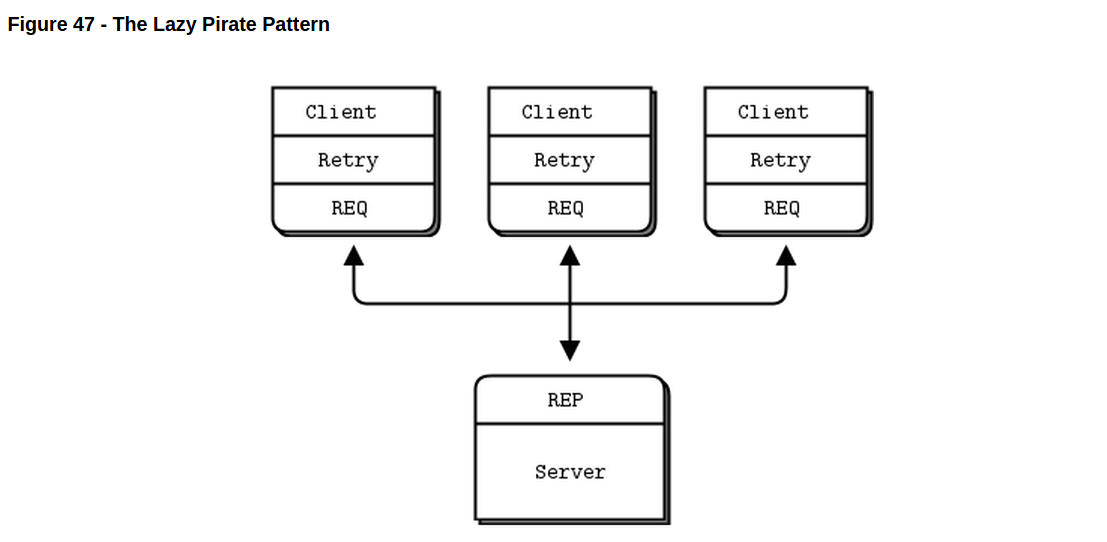
//lpclient: Lazy Pirate client in C // Lazy Pirate client // Use zmq_poll to do a safe request-reply // To run, start lpserver and then randomly kill/restart it
#include "czmq.h" #define REQUEST_TIMEOUT 2500 // msecs, (> 1000!) #define REQUEST_RETRIES 3 // Before we abandon #define SERVER_ENDPOINT "tcp://localhost:5555"
int main (void) { zctx_t *ctx = zctx_new (); printf ("I: connecting to server…\n"); void *client = zsocket_new (ctx, ZMQ_REQ); assert (client); zsocket_connect (client, SERVER_ENDPOINT);
int sequence = 0; int retries_left = REQUEST_RETRIES; while (retries_left && !zctx_interrupted) { // We send a request, then we work to get a reply char request [10]; sprintf (request, "%d", ++sequence); zstr_send (client, request);
int expect_reply = 1; while (expect_reply) { // Poll socket for a reply, with timeout zmq_pollitem_t items [] = { { client, 0, ZMQ_POLLIN, 0 } }; int rc = zmq_poll (items, 1, REQUEST_TIMEOUT * ZMQ_POLL_MSEC); if (rc == -1) break; // Interrupted
// Here we process a server reply and exit our loop if the // reply is valid. If we didn't a reply we close the client // socket and resend the request. We try a number of times // before finally abandoning:
if (items [0].revents & ZMQ_POLLIN) { // We got a reply from the server, must match sequence char *reply = zstr_recv (client); if (!reply) break; // Interrupted if (atoi (reply) == sequence) { printf ("I: server replied OK (%s)\n", reply); retries_left = REQUEST_RETRIES; expect_reply = 0; } else printf ("E: malformed reply from server: %s\n", reply);
free (reply); } else if (--retries_left == 0) { printf ("E: server seems to be offline, abandoning\n"); break; } else { printf ("W: no response from server, retrying…\n"); // Old socket is confused; close it and open a new one zsocket_destroy (ctx, client); printf ("I: reconnecting to server…\n"); client = zsocket_new (ctx, ZMQ_REQ); zsocket_connect (client, SERVER_ENDPOINT); // Send request again, on new socket zstr_send (client, request); } } } zctx_destroy (&ctx); return 0; }
// lpserver: Lazy Pirate server in C // Lazy Pirate server // Binds REQ socket to tcp://*:5555 // Like hwserver except: // - echoes request as-is // - randomly runs slowly, or exits to simulate a crash.
#include "zhelpers.h"
int main (void) { srandom ((unsigned) time (NULL));
I: normal request (1) I: normal request (2) I: normal request (3) I: simulating CPU overload I: normal request (4) I: simulating a crash
这里是client的回复:
1 2 3 4 5 6 7 8 9
I: connecting to server... I: server replied OK (1) I: server replied OK (2) I: server replied OK (3) W: no response from server, retrying... I: connecting to server... W: no response from server, retrying... I: connecting to server... E: server seems to be offline, abandoning
client使用REQ socket,并且强制性关闭/重启,因为REQ socket强制要求严格的发送/接收循环。你可以用DEALER代替,但这并不是一个良好的设计。首先,这意味着你需要模拟REQ对信封的操作(如果你忘了那是什么,不要紧,这里的好消息是你不用必须去这样做。译注:翻译的表达不出原文的味道,有点儿问题,需复查:if you’ve forgotten what that is, it’s a good sign you don’t want to have to it)。其次,这意味这可能会收到你不希望收到的回复。
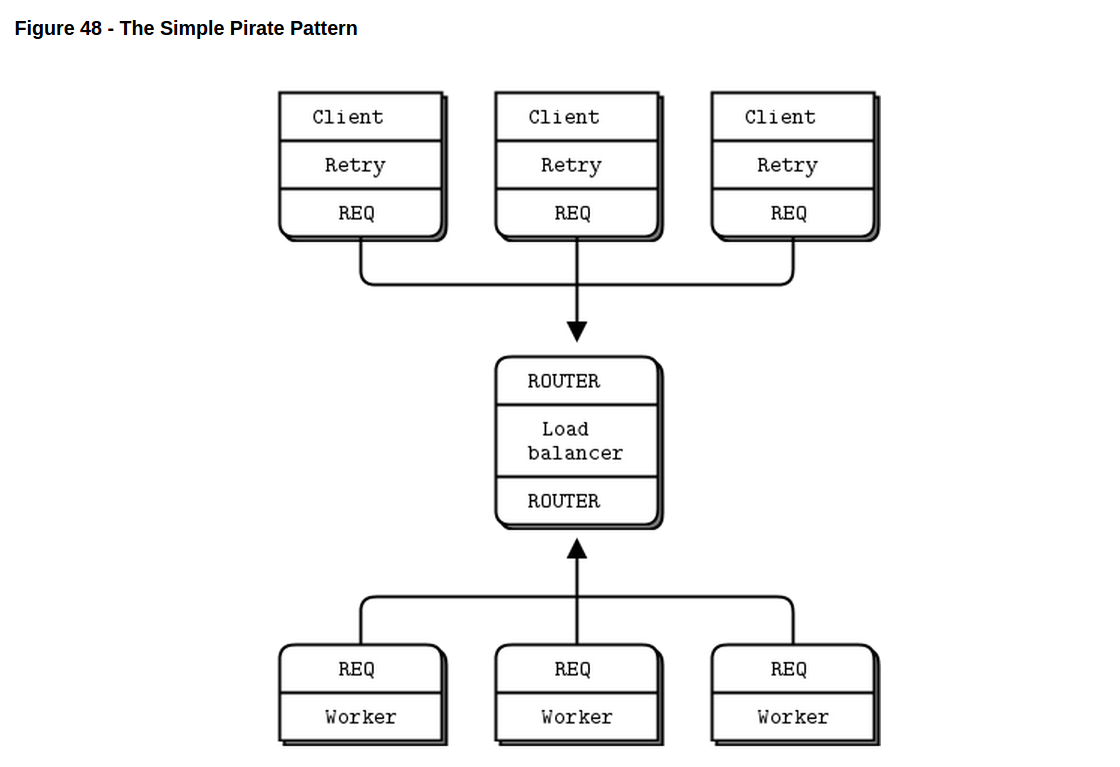
// spqueue: Simple Pirate queue in C // Simple Pirate broker // This is identical to load-balancing pattern, with no reliability // mechanisms. It depends on the client for recovery. Runs forever.
#include "czmq.h" #define WORKER_READY "\001" // Signals worker is ready
int main (void) { zctx_t *ctx = zctx_new (); void *frontend = zsocket_new (ctx, ZMQ_ROUTER); void *backend = zsocket_new (ctx, ZMQ_ROUTER); zsocket_bind (frontend, "tcp://*:5555"); // For clients zsocket_bind (backend, "tcp://*:5556"); // For workers
// Queue of available workers zlist_t *workers = zlist_new ();
// The body of this example is exactly the same as lbbroker2. while (true) { zmq_pollitem_t items [] = { { backend, 0, ZMQ_POLLIN, 0 }, { frontend, 0, ZMQ_POLLIN, 0 } }; // Poll frontend only if we have available workers int rc = zmq_poll (items, zlist_size (workers)? 2: 1, -1); if (rc == -1) break; // Interrupted
// Handle worker activity on backend if (items [0].revents & ZMQ_POLLIN) { // Use worker identity for load-balancing zmsg_t *msg = zmsg_recv (backend); if (!msg) break; // Interrupted zframe_t *identity = zmsg_unwrap (msg); zlist_append (workers, identity);
// Forward message to client if it's not a READY zframe_t *frame = zmsg_first (msg); if (memcmp (zframe_data (frame), WORKER_READY, 1) == 0) zmsg_destroy (&msg); else zmsg_send (&msg, frontend); } if (items [1].revents & ZMQ_POLLIN) { // Get client request, route to first available worker zmsg_t *msg = zmsg_recv (frontend); if (msg) { zmsg_wrap (msg, (zframe_t *) zlist_pop (workers)); zmsg_send (&msg, backend); } } } // When we're done, clean up properly while (zlist_size (workers)) { zframe_t *frame = (zframe_t *) zlist_pop (workers); zframe_destroy (&frame); } zlist_destroy (&workers); zctx_destroy (&ctx); return 0; }
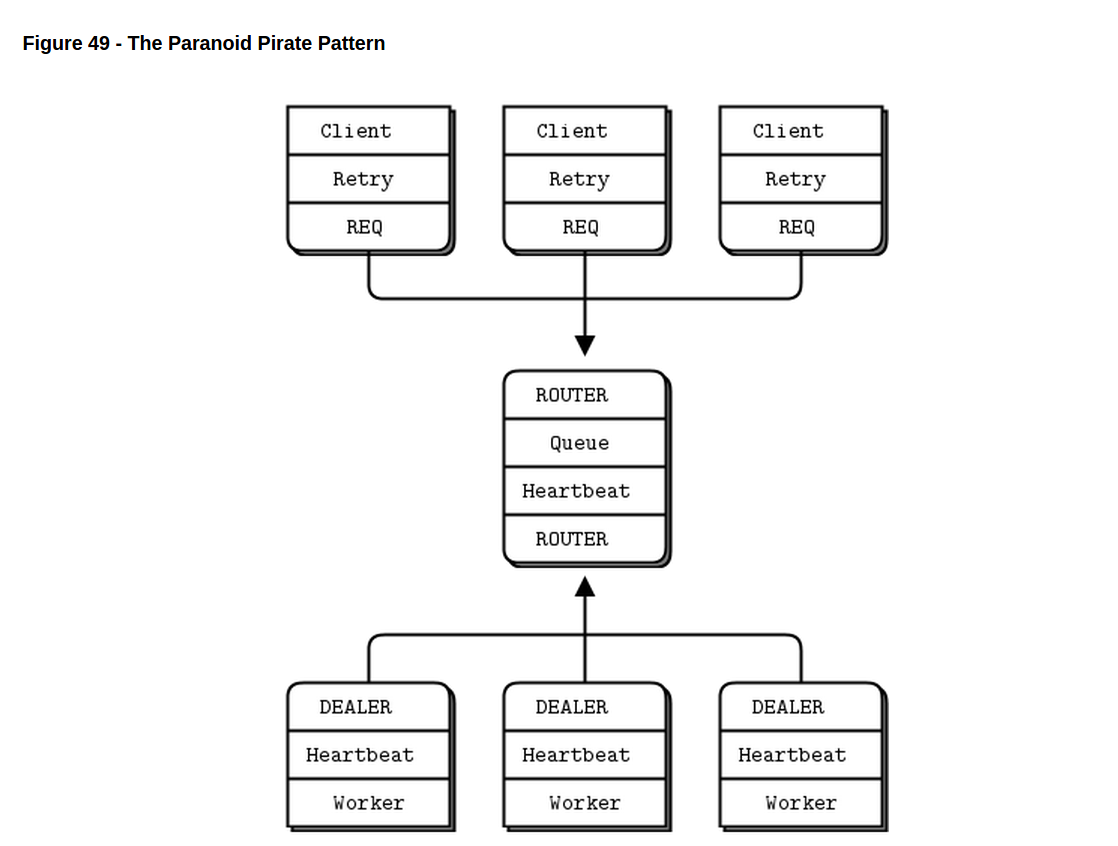
// The main task is a load-balancer with heartbeating on workers so we // can detect crashed or blocked worker tasks:
int main (void) { zctx_t *ctx = zctx_new (); void *frontend = zsocket_new (ctx, ZMQ_ROUTER); void *backend = zsocket_new (ctx, ZMQ_ROUTER); zsocket_bind (frontend, "tcp://*:5555"); // For clients zsocket_bind (backend, "tcp://*:5556"); // For workers
// List of available workers zlist_t *workers = zlist_new ();
// Send out heartbeats at regular intervals uint64_t heartbeat_at = zclock_time () + HEARTBEAT_INTERVAL;
while (true) { zmq_pollitem_t items [] = { { backend, 0, ZMQ_POLLIN, 0 }, { frontend, 0, ZMQ_POLLIN, 0 } }; // Poll frontend only if we have available workers int rc = zmq_poll (items, zlist_size (workers)? 2: 1, HEARTBEAT_INTERVAL * ZMQ_POLL_MSEC); if (rc == -1) break; // Interrupted
// Handle worker activity on backend if (items [0].revents & ZMQ_POLLIN) { // Use worker identity for load-balancing zmsg_t *msg = zmsg_recv (backend); if (!msg) break; // Interrupted
// Any sign of life from worker means it's ready zframe_t *identity = zmsg_unwrap (msg); worker_t *worker = s_worker_new (identity); s_worker_ready (worker, workers);
// Validate control message, or return reply to client if (zmsg_size (msg) == 1) { zframe_t *frame = zmsg_first (msg); if (memcmp (zframe_data (frame), PPP_READY, 1) && memcmp (zframe_data (frame), PPP_HEARTBEAT, 1)) { printf ("E: invalid message from worker"); zmsg_dump (msg); } zmsg_destroy (&msg); } else zmsg_send (&msg, frontend); } if (items [1].revents & ZMQ_POLLIN) { // Now get next client request, route to next worker zmsg_t *msg = zmsg_recv (frontend); if (!msg) break; // Interrupted zmsg_push (msg, s_workers_next (workers)); zmsg_send (&msg, backend); } // We handle heartbeating after any socket activity. First, we send // heartbeats to any idle workers if it's time. Then, we purge any // dead workers: if (zclock_time () >= heartbeat_at) { worker_t *worker = (worker_t *) zlist_first (workers); while (worker) { zframe_send (&worker->identity, backend, ZFRAME_REUSE + ZFRAME_MORE); zframe_t *frame = zframe_new (PPP_HEARTBEAT, 1); zframe_send (&frame, backend, 0); worker = (worker_t *) zlist_next (workers); } heartbeat_at = zclock_time () + HEARTBEAT_INTERVAL; } s_workers_purge (workers); } // When we're done, clean up properly while (zlist_size (workers)) { worker_t *worker = (worker_t *) zlist_pop (workers); s_worker_destroy (&worker); } zlist_destroy (&workers); zctx_destroy (&ctx); return 0; }
// We have a single task that implements the worker side of the // Paranoid Pirate Protocol (PPP). The interesting parts here are // the heartbeating, which lets the worker detect if the queue has // died, and vice versa:
int main (void) { zctx_t *ctx = zctx_new (); void *worker = s_worker_socket (ctx);
// If liveness hits zero, queue is considered disconnected size_t liveness = HEARTBEAT_LIVENESS; size_t interval = INTERVAL_INIT;
// Send out heartbeats at regular intervals uint64_t heartbeat_at = zclock_time () + HEARTBEAT_INTERVAL;
srandom ((unsigned) time (NULL)); int cycles = 0; while (true) { zmq_pollitem_t items [] = { { worker, 0, ZMQ_POLLIN, 0 } }; int rc = zmq_poll (items, 1, HEARTBEAT_INTERVAL * ZMQ_POLL_MSEC); if (rc == -1) break; // Interrupted
// To test the robustness of the queue implementation we // // simulate various typical problems, such as the worker // crashing or running very slowly. We do this after a few // cycles so that the architecture can get up and running // first: if (zmsg_size (msg) == 3) { cycles++; if (cycles > 3 && randof (5) == 0) { printf ("I: simulating a crash\n"); zmsg_destroy (&msg); break; } else if (cycles > 3 && randof (5) == 0) { printf ("I: simulating CPU overload\n"); sleep (3); if (zctx_interrupted) break; } printf ("I: normal reply\n"); zmsg_send (&msg, worker); liveness = HEARTBEAT_LIVENESS; sleep (1); // Do some heavy work if (zctx_interrupted) break; } else // When we get a heartbeat message from the queue, it means the // queue was (recently) alive, so we must reset our liveness // indicator: if (zmsg_size (msg) == 1) { zframe_t *frame = zmsg_first (msg); if (memcmp (zframe_data (frame), PPP_HEARTBEAT, 1) == 0) liveness = HEARTBEAT_LIVENESS; else { printf ("E: invalid message\n"); zmsg_dump (msg); } zmsg_destroy (&msg); } else { printf ("E: invalid message\n"); zmsg_dump (msg); } interval = INTERVAL_INIT; } else // If the queue hasn't sent us heartbeats in a while, destroy the // socket and reconnect. This is the simplest most brutal way of // discarding any messages we might have sent in the meantime:// if (--liveness == 0) { printf ("W: heartbeat failure, can't reach queue\n"); printf ("W: reconnecting in %zd msec…\n", interval); zclock_sleep (interval);
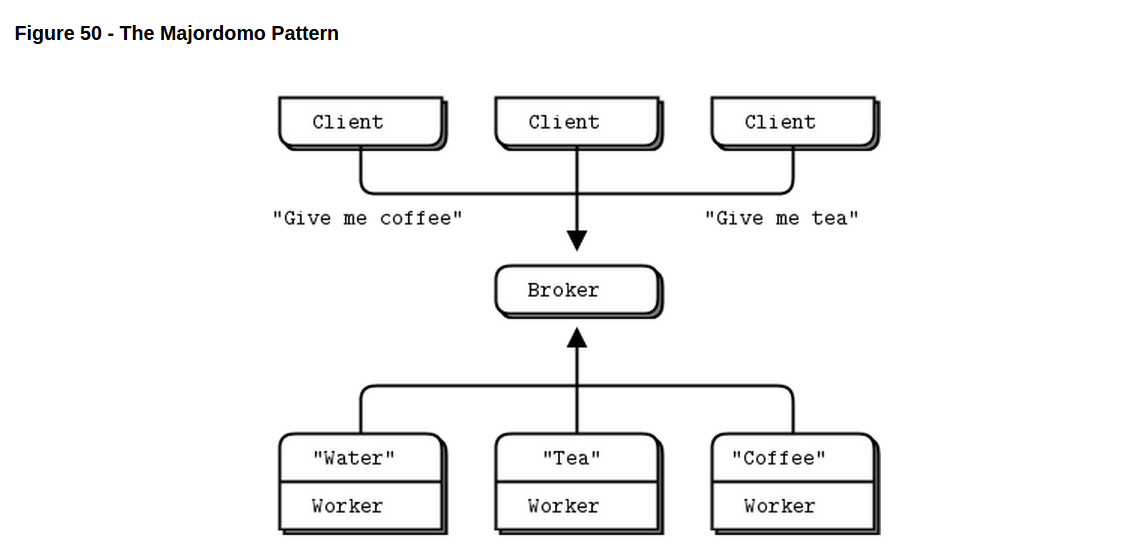
没有说明的尝试很有趣,但对真正的应用来说这并不是一个好的基础。(译注:orz…. It’s fun to experiment without specifications, but taht’s not a sensible basis for real applications.)如果我们想用另一种语言写一个worker会怎么样?我们必须读代码来看这东西是怎么工作的吗?如果我们因为某种原因想换种协议呢?甚至是一个简单的协议,如果它是成功的,那就会逐渐发展变得很复杂。
关于进度很好的一件事是在没有律师和委员会参与的情况下它能发展那么快(译注:orz…. The nice thing about progress is how fast it happens when lawyers and committees aren’t involved.)。这个一页纸的MDP说明把PPP变得更具体了。这就是我们如何去设计复杂的架构:从写协议开始,然后再去写软件实现它们。
// mdcliapi: Majordomo client API in C // mdcliapi class - Majordomo Protocol Client API // Implements the MDP/Worker spec at http://rfc.zeromq.org/spec:7.
#include "mdcliapi.h"
// Structure of our class // We access these properties only via class methods
struct _mdcli_t { zctx_t *ctx; // Our context char *broker; void *client; // Socket to broker int verbose; // Print activity to stdout int timeout; // Request timeout int retries; // Request retries };
// Connect or reconnect to broker
void s_mdcli_connect_to_broker (mdcli_t *self) { if (self->client) zsocket_destroy (self->ctx, self->client); self->client = zsocket_new (self->ctx, ZMQ_REQ); zmq_connect (self->client, self->broker); if (self->verbose) zclock_log ("I: connecting to broker at %s…", self->broker); }
// Here we have the constructor and destructor for our class:
// Constructor
mdcli_t * mdcli_new (char *broker, int verbose) { assert (broker);
// Here is the send method. It sends a request to the broker and gets // a reply even if it has to retry several times. It takes ownership of // the request message, and destroys it when sent. It returns the reply // message, or NULL if there was no reply after multiple attempts:
// Prefix request with protocol frames // Frame 1: "MDPCxy" (six bytes, MDP/Client x.y) // Frame 2: Service name (printable string) zmsg_pushstr (request, service); zmsg_pushstr (request, MDPC_CLIENT); if (self->verbose) { zclock_log ("I: send request to '%s' service:", service); zmsg_dump (request); } int retries_left = self->retries; while (retries_left && !zctx_interrupted) { zmsg_t *msg = zmsg_dup (request); zmsg_send (&msg, self->client);
zmq_pollitem_t items [] = { { self->client, 0, ZMQ_POLLIN, 0 } }; // On any blocking call, libzmq will return -1 if there was // an error; we could in theory check for different error codes, // but in practice it's OK to assume it was EINTR (Ctrl-C):
int rc = zmq_poll (items, 1, self->timeout * ZMQ_POLL_MSEC); if (rc == -1) break; // Interrupted
// If we got a reply, process it if (items [0].revents & ZMQ_POLLIN) { zmsg_t *msg = zmsg_recv (self->client); if (self->verbose) { zclock_log ("I: received reply:"); zmsg_dump (msg); } // We would handle malformed replies better in real code assert (zmsg_size (msg) >= 3);
// mdwrkapi: Majordomo worker API in C // mdwrkapi class - Majordomo Protocol Worker API // Implements the MDP/Worker spec at http://rfc.zeromq.org/spec:7.
#include "mdwrkapi.h"
// Reliability parameters #define HEARTBEAT_LIVENESS 3 // 3-5 is reasonable
// This is the structure of a worker API instance. We use a pseudo-OO // approach in a lot of the C examples, as well as the CZMQ binding:
// Structure of our class // We access these properties only via class methods
struct _mdwrk_t { zctx_t *ctx; // Our context char *broker; char *service; void *worker; // Socket to broker int verbose; // Print activity to stdout
// Heartbeat management uint64_t heartbeat_at; // When to send HEARTBEAT size_t liveness; // How many attempts left int heartbeat; // Heartbeat delay, msecs int reconnect; // Reconnect delay, msecs
int expect_reply; // Zero only at start zframe_t *reply_to; // Return identity, if any };
// We have two utility functions; to send a message to the broker and // to (re)connect to the broker:
// Send message to broker // If no msg is provided, creates one internally
// This is the recv method; it's a little misnamed because it first sends // any reply and then waits for a new request. If you have a better name // for this, let me know.
// Send reply, if any, to broker and wait for next request.
zmsg_t * mdwrk_recv (mdwrk_t *self, zmsg_t **reply_p) { // Format and send the reply if we were provided one assert (reply_p); zmsg_t *reply = *reply_p; assert (reply || !self->expect_reply); if (reply) { assert (self->reply_to); zmsg_wrap (reply, self->reply_to); s_mdwrk_send_to_broker (self, MDPW_REPLY, NULL, reply); zmsg_destroy (reply_p); } self->expect_reply = 1;
zframe_t *command = zmsg_pop (msg); if (zframe_streq (command, MDPW_REQUEST)) { // We should pop and save as many addresses as there are // up to a null part, but for now, just save one… self->reply_to = zmsg_unwrap (msg); zframe_destroy (&command); // Here is where we actually have a message to process; we // return it to the caller application:
return msg; // We have a request to process } else if (zframe_streq (command, MDPW_HEARTBEAT)) ; // Do nothing for heartbeats else if (zframe_streq (command, MDPW_DISCONNECT)) s_mdwrk_connect_to_broker (self); else { zclock_log ("E: invalid input message"); zmsg_dump (msg); } zframe_destroy (&command); zmsg_destroy (&msg); } else if (--self->liveness == 0) { if (self->verbose) zclock_log ("W: disconnected from broker - retrying…"); zclock_sleep (self->reconnect); s_mdwrk_connect_to_broker (self); } // Send HEARTBEAT if it's time if (zclock_time () > self->heartbeat_at) { s_mdwrk_send_to_broker (self, MDPW_HEARTBEAT, NULL, NULL); self->heartbeat_at = zclock_time () + self->heartbeat; } } if (zctx_interrupted) printf ("W: interrupt received, killing worker…\n"); return NULL; }
// mdbroker: Majordomo broker in C // Majordomo Protocol broker // A minimal C implementation of the Majordomo Protocol as defined in // http://rfc.zeromq.org/spec:7 and http://rfc.zeromq.org/spec:8.
// The broker class defines a single broker instance:
typedef struct { zctx_t *ctx; // Our context void *socket; // Socket for clients & workers int verbose; // Print activity to stdout char *endpoint; // Broker binds to this endpoint zhash_t *services; // Hash of known services zhash_t *workers; // Hash of known workers zlist_t *waiting; // List of waiting workers uint64_t heartbeat_at; // When to send HEARTBEAT } broker_t;
// The service class defines a single service instance:
typedef struct { broker_t *broker; // Broker instance char *name; // Service name zlist_t *requests; // List of client requests zlist_t *waiting; // List of waiting workers size_t workers; // How many workers we have } service_t;
// This method binds the broker instance to an endpoint. We can call // this multiple times. Note that MDP uses a single socket for both clients // and workers:
void s_broker_bind (broker_t *self, char *endpoint) { zsocket_bind (self->socket, endpoint); zclock_log ("I: MDP broker/0.2.0 is active at %s", endpoint); }
// This method processes one READY, REPLY, HEARTBEAT, or // DISCONNECT message sent to the broker by a worker:
// Remove & save client return envelope and insert the // protocol header and service name, then rewrap envelope. zframe_t *client = zmsg_unwrap (msg); zmsg_push (msg, zframe_dup (service_frame)); zmsg_pushstr (msg, MDPC_CLIENT); zmsg_wrap (msg, client); zmsg_send (&msg, self->socket); } else // Else dispatch the message to the requested service s_service_dispatch (service, msg); zframe_destroy (&service_frame); }
// This method deletes any idle workers that haven't pinged us in a // while. We hold workers from oldest to most recent so we can stop // scanning whenever we find a live worker. This means we'll mainly stop // at the first worker, which is essential when we have large numbers of // workers (we call this method in our critical path):
static void s_broker_purge (broker_t *self) { worker_t *worker = (worker_t *) zlist_first (self->waiting); while (worker) { if (zclock_time () < worker->expiry) break; // Worker is alive, we're done here if (self->verbose) zclock_log ("I: deleting expired worker: %s", worker->id_string);
// Get and process messages forever or until interrupted while (true) { zmq_pollitem_t items [] = { { self->socket, 0, ZMQ_POLLIN, 0 } }; int rc = zmq_poll (items, 1, HEARTBEAT_INTERVAL * ZMQ_POLL_MSEC); if (rc == -1) break; // Interrupted
// Process next input message, if any if (items [0].revents & ZMQ_POLLIN) { zmsg_t *msg = zmsg_recv (self->socket); if (!msg) break; // Interrupted if (self->verbose) { zclock_log ("I: received message:"); zmsg_dump (msg); } zframe_t *sender = zmsg_pop (msg); zframe_t *empty = zmsg_pop (msg); zframe_t *header = zmsg_pop (msg);
// tripping: Round-trip demonstrator in C // Round-trip demonstrator // While this example runs in a single process, that is just to make // it easier to start and stop the example. The client task signals to // main when it's ready.
// mdcliapi2: Majordomo asynchronuous clinet API in C // mdcliapi2 class - Majordomo Protocol Client API // Implements the MDP/Worker spec at http://rfc.zeromq.org/spec:7.
#include "mdcliapi2.h"
// Structure of our class // We access these properties only via class methods
struct _mdcli_t { zctx_t *ctx; // Our context char *broker; void *client; // Socket to broker int verbose; // Print activity to stdout int timeout; // Request timeout };
// Connect or reconnect to broker. In this asynchronous class we use a // DEALER socket instead of a REQ socket; this lets us send any number // of requests without waiting for a reply.
void s_mdcli_connect_to_broker (mdcli_t *self) { if (self->client) zsocket_destroy (self->ctx, self->client); self->client = zsocket_new (self->ctx, ZMQ_DEALER); zmq_connect (self->client, self->broker); if (self->verbose) zclock_log ("I: connecting to broker at %s…", self->broker); }
// The constructor and destructor are the same as in mdcliapi, except // we don't do retries, so there's no retries property. // --------------------------------------------------------------------- // Constructor
mdcli_t * mdcli_new (char *broker, int verbose) { assert (broker);
// The send method now just sends one message, without waiting for a // reply. Since we're using a DEALER socket we have to send an empty // frame at the start, to create the same envelope that the REQ socket // would normally make for us:
// The recv method waits for a reply message and returns that to the // caller. // --------------------------------------------------------------------- // Returns the reply message or NULL if there was no reply. Does not // attempt to recover from a broker failure, this is not possible // without storing all unanswered requests and resending them all…
// Poll socket for a reply, with timeout zmq_pollitem_t items [] = { { self->client, 0, ZMQ_POLLIN, 0 } }; int rc = zmq_poll (items, 1, self->timeout * ZMQ_POLL_MSEC); if (rc == -1) return NULL; // Interrupted
// If we got a reply, process it if (items [0].revents & ZMQ_POLLIN) { zmsg_t *msg = zmsg_recv (self->client); if (self->verbose) { zclock_log ("I: received reply:"); zmsg_dump (msg); } // Don't try to handle errors, just assert noisily assert (zmsg_size (msg) >= 4);
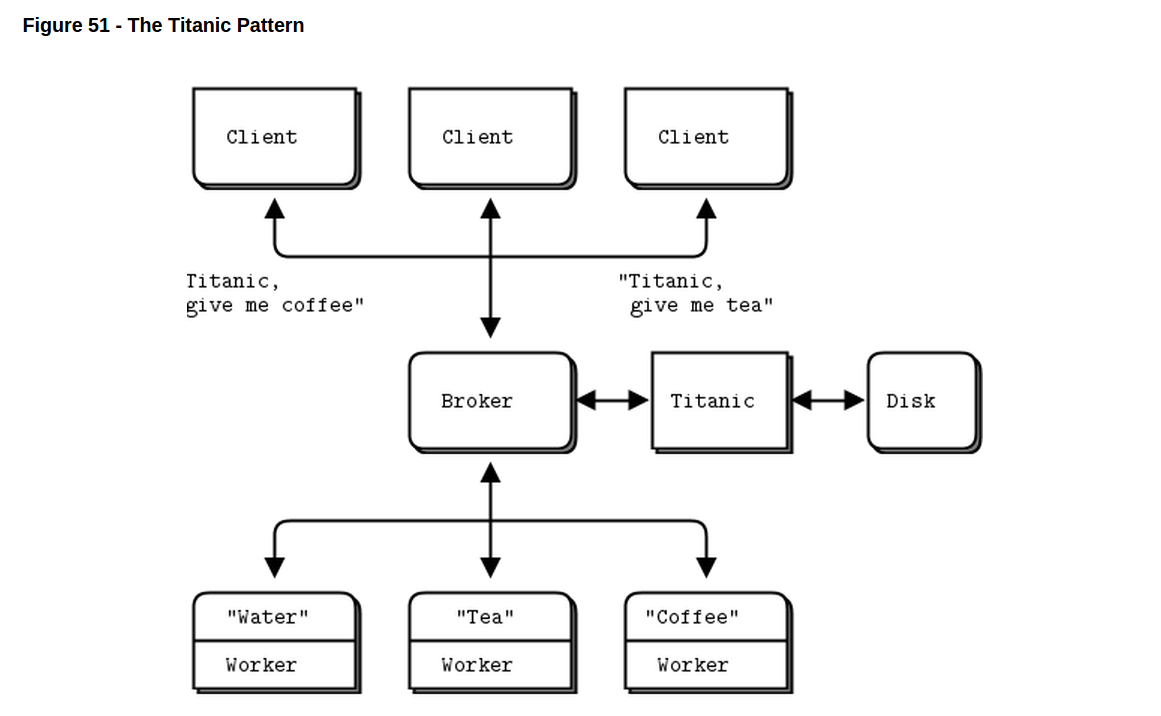
一旦你意识到管家模型是一个”可靠的”message broker的时候,你可能想去添加一些spinning rust(译注:硬盘?)(that is, ferrous-based hard disk platters)。毕竟,broker是要为整个消息系统服务的。这是个有诱惑力的想法,不过很伤感的说必须否决掉它。但简单粗暴是我的一个特长(译注:orz…. But brutal cynicism is one of my specialties)。因此,你不想在你的架构中加入持久化保障的一些原因是:
// The titanic.request task waits for requests to this service. It writes // each request to disk and returns a UUID to the client. The client picks // up the reply asynchronously using the titanic.reply service:
while (true) { // Send reply if it's not null // And then get next request from broker zmsg_t *request = mdwrk_recv (worker, &reply); if (!request) break; // Interrupted, exit
// Generate UUID and save message to disk char *uuid = s_generate_uuid (); char *filename = s_request_filename (uuid); FILE *file = fopen (filename, "w"); assert (file); zmsg_save (request, file); fclose (file); free (filename); zmsg_destroy (&request);
// Send UUID through to message queue reply = zmsg_new (); zmsg_addstr (reply, uuid); zmsg_send (&reply, pipe);
// Now send UUID back to client // Done by the mdwrk_recv() at the top of the loop reply = zmsg_new (); zmsg_addstr (reply, "200"); zmsg_addstr (reply, uuid); free (uuid); } mdwrk_destroy (&worker); }
// The titanic.reply task checks if there's a reply for the specified // request (by UUID), and returns a 200 (OK), 300 (Pending), or 400 // (Unknown) accordingly:
// The titanic.close task removes any waiting replies for the request // (specified by UUID). It's idempotent, so it is safe to call more than // once in a row:
// This is the main thread for the Titanic worker. It starts three child // threads; for the request, reply, and close services. It then dispatches // requests to workers using a simple brute force disk queue. It receives // request UUIDs from the titanic.request service, saves these to a disk // file, and then throws each request at MDP workers until it gets a // response.
static int s_service_success (char *uuid);
int main (int argc, char *argv []) { int verbose = (argc > 1 && streq (argv [1], "-v")); zctx_t *ctx = zctx_new ();
// Main dispatcher loop while (true) { // We'll dispatch once per second, if there's no activity zmq_pollitem_t items [] = { { request_pipe, 0, ZMQ_POLLIN, 0 } }; int rc = zmq_poll (items, 1, 1000 * ZMQ_POLL_MSEC); if (rc == -1) break; // Interrupted if (items [0].revents & ZMQ_POLLIN) { // Ensure message directory exists zfile_mkdir (TITANIC_DIR);
// Append UUID to queue, prefixed with '-' for pending zmsg_t *msg = zmsg_recv (request_pipe); if (!msg) break; // Interrupted FILE *file = fopen (TITANIC_DIR "/queue", "a"); char *uuid = zmsg_popstr (msg); fprintf (file, "-%s\n", uuid); fclose (file); free (uuid); zmsg_destroy (&msg); } // Brute force dispatcher char entry [] = "?…….:…….:…….:…….:"; FILE *file = fopen (TITANIC_DIR "/queue", "r+"); while (file && fread (entry, 33, 1, file) == 1) { // UUID is prefixed with '-' if still waiting if (entry [0] == '-') { if (verbose) printf ("I: processing request %s\n", entry + 1); if (s_service_success (entry + 1)) { // Mark queue entry as processed fseek (file, -33, SEEK_CUR); fwrite ("+", 1, 1, file); fseek (file, 32, SEEK_CUR); } } // Skip end of line, LF or CRLF if (fgetc (file) == '\r') fgetc (file); if (zctx_interrupted) break; } if (file) fclose (file); } return 0; }
// Here, we first check if the requested MDP service is defined or not, // using a MMI lookup to the Majordomo broker. If the service exists, // we send a request and wait for a reply using the conventional MDP // client API. This is not meant to be fast, just very simple:
static int s_service_success (char *uuid) { // Load request message, service will be first frame char *filename = s_request_filename (uuid); FILE *file = fopen (filename, "r"); free (filename);
// If the client already closed request, treat as successful if (!file) return 1;
// bstarsrv: Binary Star server in C // Binary Star server proof-of-concept implementation. This server does no // real work; it just demonstrates the Binary Star failover model.
#include "czmq.h"
// States we can be in at any point in time typedef enum { STATE_PRIMARY = 1, // Primary, waiting for peer to connect STATE_BACKUP = 2, // Backup, waiting for peer to connect STATE_ACTIVE = 3, // Active - accepting connections STATE_PASSIVE = 4 // Passive - not accepting connections } state_t;
// Events, which start with the states our peer can be in typedef enum { PEER_PRIMARY = 1, // HA peer is pending primary PEER_BACKUP = 2, // HA peer is pending backup PEER_ACTIVE = 3, // HA peer is active PEER_PASSIVE = 4, // HA peer is passive CLIENT_REQUEST = 5 // Client makes request } event_t;
// Our finite state machine typedef struct { state_t state; // Current state event_t event; // Current event int64_t peer_expiry; // When peer is considered 'dead' } bstar_t;
// We send state information this often // If peer doesn't respond in two heartbeats, it is 'dead' #define HEARTBEAT 1000 // In msecs
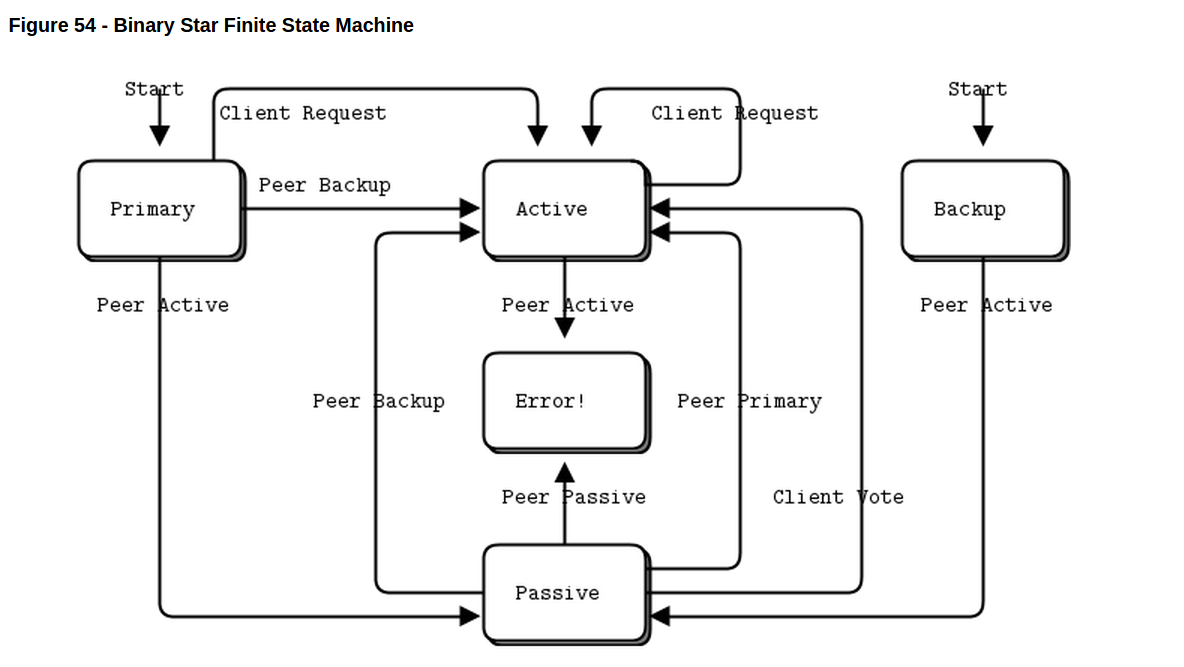
// The heart of the Binary Star design is its finite-state machine (FSM). // The FSM runs one event at a time. We apply an event to the current state, // which checks if the event is accepted, and if so, sets a new state:
// These are the PRIMARY and BACKUP states; we're waiting to become // ACTIVE or PASSIVE depending on events we get from our peer: if (fsm->state == STATE_PRIMARY) { if (fsm->event == PEER_BACKUP) { printf ("I: connected to backup (passive), ready active\n"); fsm->state = STATE_ACTIVE; } else if (fsm->event == PEER_ACTIVE) { printf ("I: connected to backup (active), ready passive\n"); fsm->state = STATE_PASSIVE; } // Accept client connections } else if (fsm->state == STATE_BACKUP) { if (fsm->event == PEER_ACTIVE) { printf ("I: connected to primary (active), ready passive\n"); fsm->state = STATE_PASSIVE; } else // Reject client connections when acting as backup if (fsm->event == CLIENT_REQUEST) exception = true; } else // These are the ACTIVE and PASSIVE states:
if (fsm->state == STATE_ACTIVE) { if (fsm->event == PEER_ACTIVE) { // Two actives would mean split-brain printf ("E: fatal error - dual actives, aborting\n"); exception = true; } } else // Server is passive // CLIENT_REQUEST events can trigger failover if peer looks dead if (fsm->state == STATE_PASSIVE) { if (fsm->event == PEER_PRIMARY) { // Peer is restarting - become active, peer will go passive printf ("I: primary (passive) is restarting, ready active\n"); fsm->state = STATE_ACTIVE; } else if (fsm->event == PEER_BACKUP) { // Peer is restarting - become active, peer will go passive printf ("I: backup (passive) is restarting, ready active\n"); fsm->state = STATE_ACTIVE; } else if (fsm->event == PEER_PASSIVE) { // Two passives would mean cluster would be non-responsive printf ("E: fatal error - dual passives, aborting\n"); exception = true; } else if (fsm->event == CLIENT_REQUEST) { // Peer becomes active if timeout has passed // It's the client request that triggers the failover assert (fsm->peer_expiry > 0); if (zclock_time () >= fsm->peer_expiry) { // If peer is dead, switch to the active state printf ("I: failover successful, ready active\n"); fsm->state = STATE_ACTIVE; } else // If peer is alive, reject connections exception = true; } } return exception; }
// This is our main task. First we bind/connect our sockets with our // peer and make sure we will get state messages correctly. We use // three sockets; one to publish state, one to subscribe to state, and // one for client requests/replies:
int main (int argc, char *argv []) { // Arguments can be either of: // -p primary server, at tcp://localhost:5001 // -b backup server, at tcp://localhost:5002 zctx_t *ctx = zctx_new (); void *statepub = zsocket_new (ctx, ZMQ_PUB); void *statesub = zsocket_new (ctx, ZMQ_SUB); zsocket_set_subscribe (statesub, ""); void *frontend = zsocket_new (ctx, ZMQ_ROUTER); bstar_t fsm = { 0 };
if (argc == 2 && streq (argv [1], "-p")) { printf ("I: Primary active, waiting for backup (passive)\n"); zsocket_bind (frontend, "tcp://*:5001"); zsocket_bind (statepub, "tcp://*:5003"); zsocket_connect (statesub, "tcp://localhost:5004"); fsm.state = STATE_PRIMARY; } else if (argc == 2 && streq (argv [1], "-b")) { printf ("I: Backup passive, waiting for primary (active)\n"); zsocket_bind (frontend, "tcp://*:5002"); zsocket_bind (statepub, "tcp://*:5004"); zsocket_connect (statesub, "tcp://localhost:5003"); fsm.state = STATE_BACKUP; } else { printf ("Usage: bstarsrv { -p | -b }\n"); zctx_destroy (&ctx); exit (0); } // We now process events on our two input sockets, and process these // events one at a time via our finite-state machine. Our "work" for // a client request is simply to echo it back:
// Set timer for next outgoing state message int64_t send_state_at = zclock_time () + HEARTBEAT; while (!zctx_interrupted) { zmq_pollitem_t items [] = { { frontend, 0, ZMQ_POLLIN, 0 }, { statesub, 0, ZMQ_POLLIN, 0 } }; int time_left = (int) ((send_state_at - zclock_time ())); if (time_left < 0) time_left = 0; int rc = zmq_poll (items, 2, time_left * ZMQ_POLL_MSEC); if (rc == -1) break; // Context has been shut down
if (items [0].revents & ZMQ_POLLIN) { // Have a client request zmsg_t *msg = zmsg_recv (frontend); fsm.event = CLIENT_REQUEST; if (s_state_machine (&fsm) == false) // Answer client by echoing request back zmsg_send (&msg, frontend); else zmsg_destroy (&msg); } if (items [1].revents & ZMQ_POLLIN) { // Have state from our peer, execute as event char *message = zstr_recv (statesub); fsm.event = atoi (message); free (message); if (s_state_machine (&fsm)) break; // Error, so exit fsm.peer_expiry = zclock_time () + 2 * HEARTBEAT; } // If we timed out, send state to peer if (zclock_time () >= send_state_at) { char message [2]; sprintf (message, "%d", fsm.state); zstr_send (statepub, message); send_state_at = zclock_time () + HEARTBEAT; } } if (zctx_interrupted) printf ("W: interrupted\n");
// Shutdown sockets and context zctx_destroy (&ctx); return 0; }
// bstarcli: Binary Star client in C // Binary Star client proof-of-concept implementation. This client does no // real work; it just demonstrates the Binary Star failover model.
#include "czmq.h" #define REQUEST_TIMEOUT 1000 // msecs #define SETTLE_DELAY 2000 // Before failing over
printf ("I: connecting to server at %s…\n", server [server_nbr]); void *client = zsocket_new (ctx, ZMQ_REQ); zsocket_connect (client, server [server_nbr]);
int sequence = 0; while (!zctx_interrupted) { // We send a request, then we work to get a reply char request [10]; sprintf (request, "%d", ++sequence); zstr_send (client, request);
int expect_reply = 1; while (expect_reply) { // Poll socket for a reply, with timeout zmq_pollitem_t items [] = { { client, 0, ZMQ_POLLIN, 0 } }; int rc = zmq_poll (items, 1, REQUEST_TIMEOUT * ZMQ_POLL_MSEC); if (rc == -1) break; // Interrupted
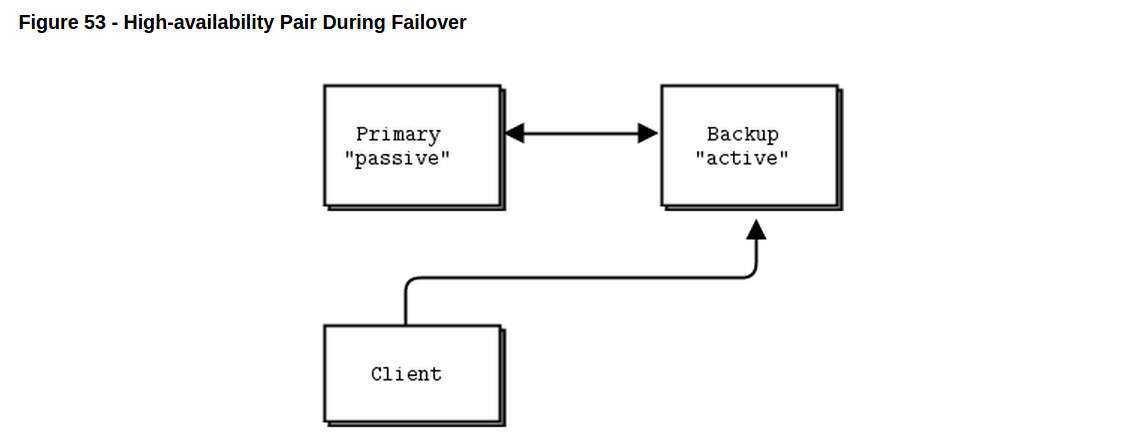
// We use a Lazy Pirate strategy in the client. If there's no // reply within our timeout, we close the socket and try again. // In Binary Star, it's the client vote that decides which // server is primary; the client must therefore try to connect // to each server in turn:
if (items [0].revents & ZMQ_POLLIN) { // We got a reply from the server, must match sequence char *reply = zstr_recv (client); if (atoi (reply) == sequence) { printf ("I: server replied OK (%s)\n", reply); expect_reply = 0; sleep (1); // One request per second } else printf ("E: bad reply from server: %s\n", reply); free (reply); } else { printf ("W: no response from server, failing over\n");
// Old socket is confused; close it and open a new one zsocket_destroy (ctx, client); server_nbr = (server_nbr + 1) % 2; zclock_sleep (SETTLE_DELAY); printf ("I: connecting to server at %s…\n", server [server_nbr]); client = zsocket_new (ctx, ZMQ_REQ); zsocket_connect (client, server [server_nbr]);
// Send request again, on new socket zstr_send (client, request); } } } zctx_destroy (&ctx); return 0; }
// States we can be in at any point in time typedef enum { STATE_PRIMARY = 1, // Primary, waiting for peer to connect STATE_BACKUP = 2, // Backup, waiting for peer to connect STATE_ACTIVE = 3, // Active - accepting connections STATE_PASSIVE = 4 // Passive - not accepting connections } state_t;
// Events, which start with the states our peer can be in typedef enum { PEER_PRIMARY = 1, // HA peer is pending primary PEER_BACKUP = 2, // HA peer is pending backup PEER_ACTIVE = 3, // HA peer is active PEER_PASSIVE = 4, // HA peer is passive CLIENT_REQUEST = 5 // Client makes request } event_t;
// Structure of our class
struct _bstar_t { zctx_t *ctx; // Our private context zloop_t *loop; // Reactor loop void *statepub; // State publisher void *statesub; // State subscriber state_t state; // Current state event_t event; // Current event int64_t peer_expiry; // When peer is considered 'dead' zloop_fn *voter_fn; // Voting socket handler void *voter_arg; // Arguments for voting handler zloop_fn *active_fn; // Call when become active void *active_arg; // Arguments for handler zloop_fn *passive_fn; // Call when become passive void *passive_arg; // Arguments for handler };
// The finite-state machine is the same as in the proof-of-concept server. // To understand this reactor in detail, first read the CZMQ zloop class.
// We send state information every this often // If peer doesn't respond in two heartbeats, it is 'dead' #define BSTAR_HEARTBEAT 1000 // In msecs
// Binary Star finite state machine (applies event to state) // Returns -1 if there was an exception, 0 if event was valid.
static int s_execute_fsm (bstar_t *self) { int rc = 0; // Primary server is waiting for peer to connect // Accepts CLIENT_REQUEST events in this state if (self->state == STATE_PRIMARY) { if (self->event == PEER_BACKUP) { zclock_log ("I: connected to backup (passive), ready as active"); self->state = STATE_ACTIVE; if (self->active_fn) (self->active_fn) (self->loop, NULL, self->active_arg); } else if (self->event == PEER_ACTIVE) { zclock_log ("I: connected to backup (active), ready as passive"); self->state = STATE_PASSIVE; if (self->passive_fn) (self->passive_fn) (self->loop, NULL, self->passive_arg); } else if (self->event == CLIENT_REQUEST) { // Allow client requests to turn us into the active if we've // waited sufficiently long to believe the backup is not // currently acting as active (i.e., after a failover) assert (self->peer_expiry > 0); if (zclock_time () >= self->peer_expiry) { zclock_log ("I: request from client, ready as active"); self->state = STATE_ACTIVE; if (self->active_fn) (self->active_fn) (self->loop, NULL, self->active_arg); } else // Don't respond to clients yet - it's possible we're // performing a failback and the backup is currently active rc = -1; } } else // Backup server is waiting for peer to connect // Rejects CLIENT_REQUEST events in this state if (self->state == STATE_BACKUP) { if (self->event == PEER_ACTIVE) { zclock_log ("I: connected to primary (active), ready as passive"); self->state = STATE_PASSIVE; if (self->passive_fn) (self->passive_fn) (self->loop, NULL, self->passive_arg); } else if (self->event == CLIENT_REQUEST) rc = -1; } else // Server is active // Accepts CLIENT_REQUEST events in this state // The only way out of ACTIVE is death if (self->state == STATE_ACTIVE) { if (self->event == PEER_ACTIVE) { // Two actives would mean split-brain zclock_log ("E: fatal error - dual actives, aborting"); rc = -1; } } else // Server is passive // CLIENT_REQUEST events can trigger failover if peer looks dead if (self->state == STATE_PASSIVE) { if (self->event == PEER_PRIMARY) { // Peer is restarting - become active, peer will go passive zclock_log ("I: primary (passive) is restarting, ready as active"); self->state = STATE_ACTIVE; } else if (self->event == PEER_BACKUP) { // Peer is restarting - become active, peer will go passive zclock_log ("I: backup (passive) is restarting, ready as active"); self->state = STATE_ACTIVE; } else if (self->event == PEER_PASSIVE) { // Two passives would mean cluster would be non-responsive zclock_log ("E: fatal error - dual passives, aborting"); rc = -1; } else if (self->event == CLIENT_REQUEST) { // Peer becomes active if timeout has passed // It's the client request that triggers the failover assert (self->peer_expiry > 0); if (zclock_time () >= self->peer_expiry) { // If peer is dead, switch to the active state zclock_log ("I: failover successful, ready as active"); self->state = STATE_ACTIVE; } else // If peer is alive, reject connections rc = -1; } // Call state change handler if necessary if (self->state == STATE_ACTIVE && self->active_fn) (self->active_fn) (self->loop, NULL, self->active_arg); } return rc; }
// Publish our state to peer int s_send_state (zloop_t *loop, zmq_pollitem_t *poller, void *arg) { bstar_t *self = (bstar_t *) arg; zstr_send (self->statepub, "%d", self->state); return 0; }
// Receive state from peer, execute finite state machine int s_recv_state (zloop_t *loop, zmq_pollitem_t *poller, void *arg) { bstar_t *self = (bstar_t *) arg; char *state = zstr_recv (poller->socket); if (state) { self->event = atoi (state); s_update_peer_expiry (self); free (state); } return s_execute_fsm (self); }
// Application wants to speak to us, see if it's possible int s_voter_ready (zloop_t *loop, zmq_pollitem_t *poller, void *arg) { bstar_t *self = (bstar_t *) arg; // If server can accept input now, call appl handler self->event = CLIENT_REQUEST; if (s_execute_fsm (self) == 0) (self->voter_fn) (self->loop, poller, self->voter_arg); else { // Destroy waiting message, no-one to read it zmsg_t *msg = zmsg_recv (poller->socket); zmsg_destroy (&msg); } return 0; }
// This is the constructor for our bstar class. We have to tell it // whether we're primary or backup server, as well as our local and // remote endpoints to bind and connect to:
// This method registers a client voter socket. Messages received // on this socket provide the CLIENT_REQUEST events for the Binary Star // FSM and are passed to the provided application handler. We require // exactly one voter per bstar instance:
int bstar_voter (bstar_t *self, char *endpoint, int type, zloop_fn handler, void *arg) { // Hold actual handler+arg so we can call this later void *socket = zsocket_new (self->ctx, type); zsocket_bind (socket, endpoint); assert (!self->voter_fn); self->voter_fn = handler; self->voter_arg = arg; zmq_pollitem_t poller = { socket, 0, ZMQ_POLLIN }; return zloop_poller (self->loop, &poller, s_voter_ready, self); }
// Register handlers to be called each time there's a state change:
// bstar: Binary Star core class in C // bstar class - Binary Star reactor
#include "bstar.h"
// States we can be in at any point in time typedef enum { STATE_PRIMARY = 1, // Primary, waiting for peer to connect STATE_BACKUP = 2, // Backup, waiting for peer to connect STATE_ACTIVE = 3, // Active - accepting connections STATE_PASSIVE = 4 // Passive - not accepting connections } state_t;
// Events, which start with the states our peer can be in typedef enum { PEER_PRIMARY = 1, // HA peer is pending primary PEER_BACKUP = 2, // HA peer is pending backup PEER_ACTIVE = 3, // HA peer is active PEER_PASSIVE = 4, // HA peer is passive CLIENT_REQUEST = 5 // Client makes request } event_t;
// Structure of our class
struct _bstar_t { zctx_t *ctx; // Our private context zloop_t *loop; // Reactor loop void *statepub; // State publisher void *statesub; // State subscriber state_t state; // Current state event_t event; // Current event int64_t peer_expiry; // When peer is considered 'dead' zloop_fn *voter_fn; // Voting socket handler void *voter_arg; // Arguments for voting handler zloop_fn *active_fn; // Call when become active void *active_arg; // Arguments for handler zloop_fn *passive_fn; // Call when become passive void *passive_arg; // Arguments for handler };
// The finite-state machine is the same as in the proof-of-concept server. // To understand this reactor in detail, first read the CZMQ zloop class.
// We send state information every this often // If peer doesn't respond in two heartbeats, it is 'dead' #define BSTAR_HEARTBEAT 1000 // In msecs
// Binary Star finite state machine (applies event to state) // Returns -1 if there was an exception, 0 if event was valid.
static int s_execute_fsm (bstar_t *self) { int rc = 0; // Primary server is waiting for peer to connect // Accepts CLIENT_REQUEST events in this state if (self->state == STATE_PRIMARY) { if (self->event == PEER_BACKUP) { zclock_log ("I: connected to backup (passive), ready as active"); self->state = STATE_ACTIVE; if (self->active_fn) (self->active_fn) (self->loop, NULL, self->active_arg); } else if (self->event == PEER_ACTIVE) { zclock_log ("I: connected to backup (active), ready as passive"); self->state = STATE_PASSIVE; if (self->passive_fn) (self->passive_fn) (self->loop, NULL, self->passive_arg); } else if (self->event == CLIENT_REQUEST) { // Allow client requests to turn us into the active if we've // waited sufficiently long to believe the backup is not // currently acting as active (i.e., after a failover) assert (self->peer_expiry > 0); if (zclock_time () >= self->peer_expiry) { zclock_log ("I: request from client, ready as active"); self->state = STATE_ACTIVE; if (self->active_fn) (self->active_fn) (self->loop, NULL, self->active_arg); } else // Don't respond to clients yet - it's possible we're // performing a failback and the backup is currently active rc = -1; } } else // Backup server is waiting for peer to connect // Rejects CLIENT_REQUEST events in this state if (self->state == STATE_BACKUP) { if (self->event == PEER_ACTIVE) { zclock_log ("I: connected to primary (active), ready as passive"); self->state = STATE_PASSIVE; if (self->passive_fn) (self->passive_fn) (self->loop, NULL, self->passive_arg); } else if (self->event == CLIENT_REQUEST) rc = -1; } else // Server is active // Accepts CLIENT_REQUEST events in this state // The only way out of ACTIVE is death if (self->state == STATE_ACTIVE) { if (self->event == PEER_ACTIVE) { // Two actives would mean split-brain zclock_log ("E: fatal error - dual actives, aborting"); rc = -1; } } else // Server is passive // CLIENT_REQUEST events can trigger failover if peer looks dead if (self->state == STATE_PASSIVE) { if (self->event == PEER_PRIMARY) { // Peer is restarting - become active, peer will go passive zclock_log ("I: primary (passive) is restarting, ready as active"); self->state = STATE_ACTIVE; } else if (self->event == PEER_BACKUP) { // Peer is restarting - become active, peer will go passive zclock_log ("I: backup (passive) is restarting, ready as active"); self->state = STATE_ACTIVE; } else if (self->event == PEER_PASSIVE) { // Two passives would mean cluster would be non-responsive zclock_log ("E: fatal error - dual passives, aborting"); rc = -1; } else if (self->event == CLIENT_REQUEST) { // Peer becomes active if timeout has passed // It's the client request that triggers the failover assert (self->peer_expiry > 0); if (zclock_time () >= self->peer_expiry) { // If peer is dead, switch to the active state zclock_log ("I: failover successful, ready as active"); self->state = STATE_ACTIVE; } else // If peer is alive, reject connections rc = -1; } // Call state change handler if necessary if (self->state == STATE_ACTIVE && self->active_fn) (self->active_fn) (self->loop, NULL, self->active_arg); } return rc; }
// Publish our state to peer int s_send_state (zloop_t *loop, zmq_pollitem_t *poller, void *arg) { bstar_t *self = (bstar_t *) arg; zstr_send (self->statepub, "%d", self->state); return 0; }
// Receive state from peer, execute finite state machine int s_recv_state (zloop_t *loop, zmq_pollitem_t *poller, void *arg) { bstar_t *self = (bstar_t *) arg; char *state = zstr_recv (poller->socket); if (state) { self->event = atoi (state); s_update_peer_expiry (self); free (state); } return s_execute_fsm (self); }
// Application wants to speak to us, see if it's possible int s_voter_ready (zloop_t *loop, zmq_pollitem_t *poller, void *arg) { bstar_t *self = (bstar_t *) arg; // If server can accept input now, call appl handler self->event = CLIENT_REQUEST; if (s_execute_fsm (self) == 0) (self->voter_fn) (self->loop, poller, self->voter_arg); else { // Destroy waiting message, no-one to read it zmsg_t *msg = zmsg_recv (poller->socket); zmsg_destroy (&msg); } return 0; }
// This is the constructor for our bstar class. We have to tell it // whether we're primary or backup server, as well as our local and // remote endpoints to bind and connect to:
// This method registers a client voter socket. Messages received // on this socket provide the CLIENT_REQUEST events for the Binary Star // FSM and are passed to the provided application handler. We require // exactly one voter per bstar instance:
int bstar_voter (bstar_t *self, char *endpoint, int type, zloop_fn handler, void *arg) { // Hold actual handler+arg so we can call this later void *socket = zsocket_new (self->ctx, type); zsocket_bind (socket, endpoint); assert (!self->voter_fn); self->voter_fn = handler; self->voter_arg = arg; zmq_pollitem_t poller = { socket, 0, ZMQ_POLLIN }; return zloop_poller (self->loop, &poller, s_voter_ready, self); }
// Register handlers to be called each time there's a state change:
// Close socket in any case, we're done with it now zsocket_destroy (ctx, client); return reply; }
// The client uses a Lazy Pirate strategy if it only has one server to talk // to. If it has two or more servers to talk to, it will try each server just // once:
int endpoints = argc - 1; if (endpoints == 0) printf ("I: syntax: %s <endpoint> …\n", argv [0]); else if (endpoints == 1) { // For one endpoint, we retry N times int retries; for (retries = 0; retries < MAX_RETRIES; retries++) { char *endpoint = argv [1]; reply = s_try_request (ctx, endpoint, request); if (reply) break; // Successful printf ("W: no response from %s, retrying…\n", endpoint); } } else { // For multiple endpoints, try each at most once int endpoint_nbr; for (endpoint_nbr = 0; endpoint_nbr < endpoints; endpoint_nbr++) { char *endpoint = argv [endpoint_nbr + 1]; reply = s_try_request (ctx, endpoint, request); if (reply) break; // Successful printf ("W: no response from %s\n", endpoint); } } if (reply) printf ("Service is running OK\n");
printf ("I: service is ready at %s\n", argv [1]); while (true) { zmsg_t *request = zmsg_recv (server); if (!request) break; // Interrupted // Fail nastily if run against wrong client assert (zmsg_size (request) == 2);
// If not a single service replies within this time, give up #define GLOBAL_TIMEOUT 2500
int main (int argc, char *argv []) { if (argc == 1) { printf ("I: syntax: %s <endpoint> …\n", argv [0]); return 0; } // Create new freelance client object flclient_t *client = flclient_new ();
// Connect to each endpoint int argn; for (argn = 1; argn < argc; argn++) flclient_connect (client, argv [argn]);
// Send a bunch of name resolution 'requests', measure time int requests = 10000; uint64_t start = zclock_time (); while (requests--) { zmsg_t *request = zmsg_new (); zmsg_addstr (request, "random name"); zmsg_t *reply = flclient_request (client, &request); if (!reply) { printf ("E: name service not available, aborting\n"); break; } zmsg_destroy (&reply); } printf ("Average round trip cost: %d usec\n", (int) (zclock_time () - start) / 10);
flclient_destroy (&client); return 0; }
// Here is the flclient class implementation. Each instance has a // context, a DEALER socket it uses to talk to the servers, a counter // of how many servers it's connected to, and a request sequence number:
struct _flclient_t { zctx_t *ctx; // Our context wrapper void *socket; // DEALER socket talking to servers size_t servers; // How many servers we have connected to uint sequence; // Number of requests ever sent };
// This method does the hard work. It sends a request to all // connected servers in parallel (for this to work, all connections // must be successful and completed by this time). It then waits // for a single successful reply, and returns that to the caller. // Any other replies are just dropped:
// flcliapi: Freelance client API in C // flcliapi class - Freelance Pattern agent class // Implements the Freelance Protocol at http://rfc.zeromq.org/spec:10
#include "flcliapi.h"
// If no server replies within this time, abandon request #define GLOBAL_TIMEOUT 3000 // msecs // PING interval for servers we think are alive #define PING_INTERVAL 2000 // msecs // Server considered dead if silent for this long #define SERVER_TTL 6000 // msecs
// This API works in two halves, a common pattern for APIs that need to // run in the background. One half is an frontend object our application // creates and works with; the other half is a backend "agent" that runs // in a background thread. The frontend talks to the backend over an // inproc pipe socket:
// Structure of our frontend class
struct _flcliapi_t { zctx_t *ctx; // Our context wrapper void *pipe; // Pipe through to flcliapi agent };
// This is the thread that handles our real flcliapi class static void flcliapi_agent (void *args, zctx_t *ctx, void *pipe);
// To implement the connect method, the frontend object sends a multipart // message to the backend agent. The first part is a string "CONNECT", and // the second part is the endpoint. It waits 100msec for the connection to // come up, which isn't pretty, but saves us from sending all requests to a // single server, at startup time:
// Here we see the backend agent. It runs as an attached thread, talking // to its parent over a pipe socket. It is a fairly complex piece of work // so we'll break it down into pieces. First, the agent manages a set of // servers, using our familiar class approach:
// Simple class for one server we talk to
typedef struct { char *endpoint; // Server identity/endpoint uint alive; // 1 if known to be alive int64_t ping_at; // Next ping at this time int64_t expires; // Expires at this time } server_t;
// We build the agent as a class that's capable of processing messages // coming in from its various sockets:
// Simple class for one background agent
typedef struct { zctx_t *ctx; // Own context void *pipe; // Socket to talk back to application void *router; // Socket to talk to servers zhash_t *servers; // Servers we've connected to zlist_t *actives; // Servers we know are alive uint sequence; // Number of requests ever sent zmsg_t *request; // Current request if any zmsg_t *reply; // Current reply if any int64_t expires; // Timeout for request/reply } agent_t;
int rc = zmq_poll (items, 2, (tickless - zclock_time ()) * ZMQ_POLL_MSEC); if (rc == -1) break; // Context has been shut down
if (items [0].revents & ZMQ_POLLIN) agent_control_message (self);
if (items [1].revents & ZMQ_POLLIN) agent_router_message (self);
// If we're processing a request, dispatch to next server if (self->request) { if (zclock_time () >= self->expires) { // Request expired, kill it zstr_send (self->pipe, "FAILED"); zmsg_destroy (&self->request); } else { // Find server to talk to, remove any expired ones while (zlist_size (self->actives)) { server_t *server = (server_t *) zlist_first (self->actives); if (zclock_time () >= server->expires) { zlist_pop (self->actives); server->alive = 0; } else { zmsg_t *request = zmsg_dup (self->request); zmsg_pushstr (request, server->endpoint); zmsg_send (&request, self->router); break; } } } } // Disconnect and delete any expired servers // Send heartbeats to idle servers if needed zhash_foreach (self->servers, server_ping, self->router); } agent_destroy (&self); }
该API的实现相当复杂,使用了两个我们以前没有见过的技巧:
多线程API: 该client API 包括两部分,一个同步的flciapi类跑在应用线程中,一个异步的agent类跑在后台线程中。回忆下zmq怎么使多线程应用的创建变得容易的。该flcliapi和agent类通过一个inproc socket使用message相互通信。所有的zmq部分(例如创建和销毁context)被隐藏在API中。该agent实际上就像一个小型的broker,在后台跟server通信,好让在我们发起一个请求的时候,它能尽最大努力连接一个它认为在线可用的server。